Visuelle Exploration zweier musealer Sammlungen

Überblick
Die Neukonzeption der Online-Sammlungen der Staatlichen Museen zu Berlin ist eines der wichtigsten und umfassendsten Projekte innerhalb des Teilprojekts Visitor Journeys neu gedacht. Ziel ist es, die Objekte der Staatlichen Museen zu Berlin auch im virtuellen Raum angemessen und zeitgemäß zur Verfügung zu stellen. Die Forschungskooperation mit dem Urban Complexity Lab der Fachhochschule Potsdam ist Teil dieser Neukonzeption, indem sie die Möglichkeiten der Visualisierung und Exploration heterogener Sammlungsbestände untersucht. Mit Methoden aus dem Interfacedesign, der Human-Computer-Interaction und der Informationsvisualisierung wurden in einem interdisziplinären Team innovative und relevante Zugänge erforscht und prototypisch umgesetzt. Als Ziel wurde formuliert, dass die Sammlungen der Staatlichen Museen zu Berlin in ihrer heterogenen Zusammensetzung erfasst und die verschiedenen Objektarten, Fachdisziplinen und Spezifika im Ganzen und im Detail visualisiert werden. So sollte ein Überblick über die Vielfalt der Bestände der Staatlichen Museen zu Berlin verdeutlicht, aber auch ein Einstieg in die spezifischen Zusammensetzungen der Sammlungen ermöglicht werden.
Bibliographische Angaben
- Institution
- Staatliche Museen zu Berlin – Preußischer Kulturbesitz
- Teilprojekt
- (De-)Coding Culture. Kulturelle Kompetenz im Digitalen Raum
- Autor*innen
- Katharina Fendius, Stephanie Thom, Viktoria Brüggemann, Mark-Jan Bludau, Marian Dörk
- Veröffentlicht
- 15.12.2020
- Lizenz der Publikation
- CC BY 4.0
- Kontakt
- Timo Schuhmacher
Staatliche Museen zu Berlin
m4p0.m1@smb.spk-berlin.de
Vorüberlegungen
Die Staatlichen Museen zu Berlin sind ein Verbund aus fünfzehn verschiedenen Sammlungen und vier Instituten. In ihren Beständen befinden sich rund 5 Millionen Objekte der europäischen und außereuropäischen Kunst, Archäologie und Ethnologie aus nahezu allen Nationen, Kulturen und Zeiten. Die siebzehn verschiedenen Museen vor Ort werden jährlich von über zwei Millionen Besucher*innen besichtigt. Hinzu kommen digitale Besucher*innen und Nutzer*innen der Webseiten, der verschiedenen Online-Datenbanken und der digitalen Angebote. So sprechen die Staatlichen Museen zu Berlin mit ihren Inhalten in und aus ihren Sammlungen sehr unterschiedliche Zielpublika, mit jeweils eigenen Bedürfnissen und Interessen, an und bieten damit eine einzigartige Ausgangslage für innovative Ansätze auf dem Gebiet objektbasierter und nutzer*innenzentrierter Forschungen.
Die Neukonzeption der Online-Sammlungen der Staatlichen Museen zu Berlin ist eines der wichtigsten und umfassendsten Projekte innerhalb des Teilprojekts Visitor Journeys neu gedacht. Ziel ist es, die Objekte der Staatlichen Museen zu Berlin auch im virtuellen Raum angemessen und zeitgemäß zur Verfügung zu stellen. Um sich diesem Ziel zu nähern wurde, auf Basis der umfassenden Grundlagenforschung zu Beginn des Teilprojekts, angenommen, dass sich die Motivationen und die damit einhergehenden Bedürfnisse digitaler Besucher*innen und Nutzer*innen individuell unterscheiden. Darauf aufbauend und von den Objekten der Staatlichen Museen zu Berlin ausgehend, wurden verschiedene intuitive und bedarfsorientierte Zugangsmöglichkeiten zu den Online-Sammlungen konzipiert und entwickelt. Die Formate RECHERCHE, THEMEN und TOUREN ermöglichen ein individuelles (Neu-)Erleben der Sammlungen und öffnen den Blick für die Multiperspektivität von Objekten und sammlungsübergreifende Zusammenhänge. Die Forschungskooperation mit dem Urban Complexity Lab der Fachhochschule Potsdam ist Teil dieser Neukonzeption, indem sie die Möglichkeiten der Visualisierung und Exploration heterogener Sammlungsbestände untersucht. Mit Methoden aus dem Interfacedesign, der Human-Computer-Interaction und der Informationsvisualisierung wurden in einem interdisziplinären Team innovative und relevante Zugänge erforscht und prototypisch umgesetzt.
Ausgangspunkt der Forschungskooperation war es, Zusammenhänge zwischen den Sammlungen und Objekten der Staatlichen Museen zu Berlin so herauszuarbeiten, dass einerseits die Heterogenität und andererseits die Individualität der Sammlungen sichtbar wird. Als Ziel wurde formuliert, dass die Sammlungen der Staatlichen Museen zu Berlin in ihrer heterogenen Zusammensetzung erfasst und die verschiedenen Objektarten, Fachdisziplinen und Spezifika im Ganzen und im Detail visualisiert werden. So sollte ein Überblick über die Vielfalt der Bestände der Staatlichen Museen zu Berlin verdeutlicht, aber auch ein Einstieg in die spezifischen Zusammensetzungen der Sammlungen ermöglicht werden.
Es sollten konkrete Vorschläge für die digitale Präsentation mehrerer Sammlungen entwickelt werden, die auf konzeptionellen Ansätzen wie denen des Informationsflaneurs (Dörk, Carpendale and Williamson 2011), der Monadischen Exploration (Dörk, Comber, and Dade-Robertson 2014) und der Generous Interfaces (Whitelaw 2015) aufbauen und die meist linearen Anordnungen virtueller Museumspräsentationen, mit objektbezogenen Informationen und Bildern sowie einer klassischen Volltextsuche und facettierten Filterung, aufbrechen. Denn diese Formen der Informationssuche und -recherche erfordern ein konkretes Interesse der Suchenden und werden den heterogenen und umfangreichen Beständen musealer Sammlungen nur bedingt gerecht, wenn es um ein assoziatives, Interessen-getriebenes Durchstöbern oder die systematische Untersuchung von Sammlungen und Beständen geht. Hier setzt das Vorhaben mit dem Ziel an, übergreifende Zusammenhänge und Resonanzen zwischen den Beständen und über Sammlungsgrenzen hinweg aufzugreifen und dynamische, interaktive Arrangements zu entwickeln, die die assoziative Exploration von Beständen anregen und ein Interesse für die Sammlungen der Staatlichen Museen zu Berlin wecken.
Es gibt bereits eine Vielzahl an Arbeiten im Bereich der Sammlungsvisualisierung, welche die kulturhistorischen Artefakte und Facetten von Sammlungen in Form visueller Interfaces sichtbar und erfahrbar machen (Windhager et al. 2018). Ein Großteil dieser Arbeiten widmet sich einzelnen Sammlungen, die jeweils einer spezifischen Systematik folgen und eine geringe Vielfalt an Objektgattungen aufweisen (z.B. Gortana et al. 2018). Im Rahmen dieser Forschungskooperation sollten konkrete Ansätze zur visuellen und assoziativen Exploration von Sammlungen und ein funktionaler Prototyp für zwei unterschiedliche Sammlungen der Staatlichen Museen zu Berlin mit verschiedenen Objektgattungen entwickelt werden, um diesen in die neu konzipierten Online-Sammlungen zu implementieren. Zentrale Fragestellungen waren:
- Wie können sammlungsübergreifende Visualisierungen verschiedenartiger Artefakte konzipiert und entwickelt werden, sodass bei Besucher*innen Interesse an und Verständnis für die Bestände angeregt wird?
- Wie können explorative Visualisierungen helfen, Schnittmengen und Gemeinsamkeiten zwischen den heterogenen Sammlungsbeständen der Staatlichen Museen zu Berlin zu verdeutlichen und neue Fragestellungen zu den Objekten sowie Sammlungen aufzuwerfen?
- Wie lässt sich eine verbesserte Suchfunktion für das Internet konzipieren und in ein exploratives Interface integrieren?
Auswahl der Bestände
Um aus der Vielzahl der Bestände und Sammlungen der Staatlichen Museen zu Berlin eine Auswahl für das Visualisierungsvorhaben zu treffen, wurden verschiedene Aspekte wie beispielsweise der Umfang der erfassten Objekte und die Erschließungstiefe der Objektdaten berücksichtigt. Da ein wichtiges Ziel innerhalb des Forschungsprojekts war, über einzelne Fachdisziplinen hinausgehende, inhaltliche Korrespondenzen herauszuarbeiten, wurden der Bestand der Alten Nationalgalerie, als Teil der Sammlungen der Nationalgalerie, sowie Objekte aus der Sammlung des Museums Europäischer Kulturen ausgewählt. Beide Bestände enthalten vielfältige Objekte und unterschiedliche Objektgattungen, die wichtige Quellen für ihre jeweiligen Fachdisziplinen sind. Während die Sammlung der Alten Nationalgalerie eine der umfangreichsten Epochensammlungen für die Kunst des 19. und frühen 20. Jahrhunderts ist, findet sich im Museum Europäischer Kulturen eine der größten Sammlungen zur Alltagskultur und Populärkunst in Europa. Die Kontraste und Gegensätze, aber auch die Gemeinsamkeiten beider Bestände sollten überprüft und damit Sammlungsgrenzen überwunden werden. Darüber hinaus sollten Potenziale zur Darstellung erweiterter Objektbiografien im Einzelnen und die Einordnung in verbindende, übergreifende thematische Zusammenhänge für Objekte des 19. Jahrhunderts im Ganzen ausgelotet werden.
Um eine Vorstellung von den ausgewählten Beständen zu erhalten, wurden mithilfe eines standardisierten Leitfragebogens Gespräche mit zwei Kurator*innen der beteiligten Museen geführt. Diese bilden die Basis der nachfolgenden Beschreibungen beider Bestände. Neben inhaltlichen Impulsen zu den Sammlungen werden dabei auch kurze Erläuterungen zu den Datenbeständen sowie eine erste Einschätzung der beteiligten Kurator*innen zu den Potenzialen der Anwendung deutlich.
Der Bestand der Alten Nationalgalerie
Die Alte Nationalgalerie ist Teil der Nationalgalerie Berlin, welche weitere Museen und Bestände zur Kunst des 19., 20. und 21. Jahrhunderts umfasst:
- Die Neue Nationalgalerie
- Der Hamburger Bahnhof
- Die Sammlung Scharf-Gerstenberg
- Das Museum Berggruen
- Die Friedrichswerdersche Kirche
Im Gegensatz zu vielen anderen Nationalgalerien wurde die Nationalgalerie Berlin im ausgehenden 19. Jahrhundert als Museum für zeitgenössische Kunst gegründet. Die Alte Nationalgalerie „[…] ist das Stammhaus. Aus dieser Keimzelle ist das große Gebilde Nationalgalerie entstanden und hat sich dann immer weiter ausdifferenziert in die verschiedenen Häuser […].“[Interview Nr. 1, S. 1]. Die Objektauswahl entsprach dem stilistischen Zeitgeist, „[…] führte aber auch revolutionäre, neue Kunstauffassungen wie den Impressionismus dem heutigen Kanon des 19. Jahrhunderts hinzu, offizielle Auftragskunst steht neben freier, zunehmend von Auftraggebern unabhängiger Kunst, die sich auf dem Kunstmarkt und bei Sammlern durchsetzte.“ [Interview Nr. 1, S. 4] Über die Zeit ist ein Zusammenschluss von Objekten wegweisender Künstler*innen der Malerei und Bildhauerei entstanden: „[…] in unserem Bestand sind beide Gattungen tatsächlich annähernd paritätisch vertreten, also circa 2.000 Objekte Malerei und circa 2.000 Objekte Bildhauerei.“ [Interview Nr. 1, S. 1].



Betrachtet man den Erschließungsgrad, so ist der Bestand der Alten Nationalgalerie zu 90% im Museumsdokumentationssystem digital erfasst. Während des Gesprächs mit der Kuratorin wurde das Vorgehen der Dokumentation exemplarisch für das Fachgebiet Bildhauerei besprochen. So ist es für „[…] ein Werk der Bildhauerei nur die Hälfte der Wahrheit […]” [Interview Nr. 1, S. 8], wenn bei der Datierung von nur einer Angabe ausgegangen werden kann. Fragen wie „[…] wann ist ein Entwurf entstanden und datiert, aber wann ist das reale Objekt, […] eigentlich entstanden[…],“ [Interview Nr. 1, S. 8] müssen hier berücksichtigt werden. Hinsichtlich der Potenziale einer Visualisierung waren zwei Fragen von besonderem Interesse:
- Welche wichtigen sammlungsbezogenen Zusammenhänge können im Museumsdokumentationsystem nur schwer visualisiert werden?
- Wo sehen Sie sammlungsübergreifende Themen, die man über die Anwendung visualisieren könnte?
Am Beispiel des Nachlasses von Karl Friedrich Schinkel wurden sammlungshistorische Aufteilungen und mögliche Schnittmengen innerhalb der Staatlichen Museen zu Berlin deutlich, die mithilfe der explorativen Visualisierung „[…] eben diese verschiedenen Bestände der SMB zu einem großen Ganzen […]“ [Interview Nr. 1, S. 4] zusammenbringen können:
„Der Schinkelbestand ist vielleicht ganz interessant. War der Nachlass gezielt als ‚Schinkelmuseum‘ in der Bauakademie zusammengetragen und später von der Nationalgalerie betreut worden, das heißt, neben Gemälden auch Pläne, innerhalb der Sammlung der Handzeichnungen auch die Zeichnungen Schinkels, so haben im Laufe der musealen Neuorganisation und Bestandsverschiebungen und Spezialisierungen innerhalb der SMB diese Teile Eingang ins Kupferstichkabinett beziehungsweise in die Kunstbibliothek gefunden“ [Interview Nr. 1, S. 4] So lasse sich neben den einzelnen Objektgeschichten „[…] auch die Historie wieder erleben. Man hat nämlich früher sehr viel globaler und im Gesamten gesammelt. Man hat gar nicht so in diese kleinen Fachportionen eingeteilt, sondern man wollte ein globales Bild haben. Genau dieses Globale kann man vielleicht wieder durch diese Anwendung dann irgendwann mal wieder erleben.“ [Interview Nr. 1, S. 4].
Der Bestand des Museums Europäischer Kulturen
Das Museum Europäischer Kulturen besitzt aktuell circa 285.000 Objekte (vgl. Tietmeyer et al. 2019, S. 7). Es handelt sich dabei um materielles und immaterielles Kulturerbe aus ganz Europa, von Alltagsgegenständen über Druckgrafik und Fotografien bis hin zu thematischen Spezialsammlungen wie etwa zur religiösen Alltagspraxis. Die Objekte stammen historisch bedingt vor allem aus Deutschland sowie Ost- und Südosteuropa.
„Das Museum Europäischer Kulturen klingt jetzt so neu, aber es ist in erster Linie eine kulturhistorische und ethnografische Sammlung, die über 100 Jahre alt ist. Wir haben eben auch Bestände aus der Anfangszeit. Das Besondere ist, dass diese Sammlung immer noch wächst. Wir beschäftigen uns mit Alltagskultur im weitesten Sinne und die umfasst alle Bereiche des täglichen Lebens, aber eben auch des Jahreslaufes und des Lebenslaufes.“ [Interview Nr. 2, S. 1].



Das Sammeln gegenwärtiger Themenbereiche und des immateriellen Kulturerbes nimmt einen immer stärkeren Fokus ein: „Was das Gegenwartssammeln anbelangt, gibt es verschiedene Aspekte. Wir haben zum Beispiel Europa und die Welt als Thema […] oder Identitätsbildungsprozesse.“ [Interview Nr. 2, S. 3] Auch alte Kulturtechniken, Bräuche und Traditionen werden im Museum mit Hilfe von Objekten und kulturellen Ausdrucksformen gesammelt und dem Besucher vermittelt: „Wir haben zum Beispiel eine große Sammlung an Blaudruckmodeln und Teile einer Blaudruckwerkstatt. Blaudruck gehört zum immateriellen Kulturerbe der Menschheit, weil dieses Handwerk in vielen Regionen Europas und darüber hinaus immer noch betrieben wird.“ [Interview Nr. 2, S. 3].
Eine Herausforderung ist das Inventarisieren und Digitalisieren der umfangreichen Bestände. Grundsätzlich sind Beschreibungstexte, Maße, Material, die Identnummer und auch eine systematische Einordnung der Objekte auf Karteikarten vorhanden. Seit 2003 werden die neu hinzukommenden Objekte ausschließlich digital inventarisiert. Viele Objekte müssen digital nacherfasst, ihre Datensätze angereichert und Fotografien erstellt werden. Gerade die inhaltliche Schwerpunktsetzung der Dokumentation setzt Daten voraus, die dezidiert verzeichnet werden müssen, um das Objekt besser einordnen zu können. Je nach Objektart wird sehr genau zwischen Erwerbs-, Gebrauchs-, Herstellungs- oder auch Druckort unterschieden. „Der geografische Bezug ist auf jeden Fall sehr wichtig. Was aber auch wichtig ist, ist der soziale Bezug, aus welchem Haushalt oder Milieu ein Objekt gekommen ist. Dann kann es zwar woanders hergestellt worden sein, aber hier ist die Frage wichtig, wer es genutzt hat. Deswegen haben wir oft mehrere geografische Angaben“ [Interview Nr. 2, S. 7].
Betrachtet man die Vielseitigkeit des Museums Europäischer Kulturen, so lassen sich sowohl verschiedene Zusammenhänge innerhalb der Sammlungen als auch zu den anderen Sammlungen der Staatlichen Museen zu Berlin in einem Geflecht von verschiedenen Beziehungen darstellen. Durch die digitale Anreicherung eines Objektes können auch Facetten, die sonst nicht abbildbar wären, sichtbar gemacht werden: „Es gibt Lamellenbilder […], bei denen man aus einer Perspektive das eine Motiv sieht, wenn man aus einem anderen Winkel schaut, sieht man das andere […].“ [Interview Nr. 2, S. 1]. Ein weiteres Beispiel ist die detaillierte Erläuterung zur Mechanik des historischen Weihnachtsberges aus dem Erzgebirge. Auch das Zusammenspiel verschiedener Medien, durch das Einbinden von Audio- und Videoelementen sowie Animationen, helfen dabei Funktionsweisen, Klänge oder auch Produktionsvorgänge zu verdeutlichen.
Die Möglichkeiten der Erweiterung von Objektbiografien in Zusammenhang mit anderen Sammlungen der Staatlichen Museen zu Berlin lassen sich sehr gut mit Gegenständen aus dem Museum Europäischer Kulturen umsetzen. „Da gibt es eine ganze Menge Potenzial. Weil wir von den Materialien und Gegenständen her so vielfältige Sammlungen haben, glaube ich, dass wir da auch eine Schnittstelle zu vielen Sammlungen der SMB hätten, […]” [Interview Nr. 2, S. 2].
Werkzeuge, Kleidungsstücke oder andere Objekte befinden sich in den Beständen des Museums Europäischer Kulturen und werden gleichzeitig auf Gemälden der Alten Nationalgalerie thematisiert. Eine potentielle visuelle Verbindung der Sammlungen mithilfe der Objekte erlaubt den Besucher*innen und Forscher*innen, verschiedene Blickwinkel auf die Artefakte zu gewinnen: „Ich recherchierte zum Thema Stern […]. Wenn man mit so einem Thema in die verschiedenen Sammlungen der SMB guckt, entdeckt man einiges. Seien es die Ordenssterne auf Gemälden von Generälen […], [oder] auf antiken Münzen“ [Interview Nr. 2, S. 6]. Somit lassen sich Schnittmengen erkennen, Gemeinsamkeiten eruieren und Sammlungsgrenzen thematisch überwinden.
Prozess und Vorgehen
Der Projektprozess entsprach einem iterativen Vorgehen, in welchem wiederkehrende Feedbackgespräche sich mit offenen Kreativmethoden und einem strukturierten Designprozess sowie dem Prototyping abwechseln und gegenseitig beeinflussen (siehe Abb. unten). Im Modus des Co-Designs, also der kooperativen Gestaltung, sollten Sammlungsexpert*innen der Museen in die Entwicklung eingebunden werden (Dörk et al. 2020; Chen, Dörk, and Dade-Robertson 2014). Die Einbindung von Expert*innen aus den Museen war dabei genauso wichtig wie die Einbindung fachfremder Personen, um die Bedürfnisse und Anforderungen an den entstehenden Prototypen im Sinne eines „Grounded Visualization Process“ zu verstehen und berücksichtigen zu können (Isenberg et al. 2008). Visualisierung wurde in diesem Entwicklungsprozess nicht nur als Ergebnis verstanden, sondern vielmehr als interdisziplinäre Forschungsmethode per se, welche neue Erkenntnisse bereitstellt, aber ebenso fächerübergreifende Diskussionen anregt (Hinrichs, Forlini, and Moynihan 2019) und die Perspektiven auf die musealen Objekte und Daten öffnet.

Co-Design-Workshop
Zu Beginn des Projekts (und vor Beginn der Covid19-Pandemie) wurde ein Co-Design-Workshop in Berlin durchgeführt (siehe Abb. oben), an dem neben dem Projektteam auch Mitarbeiter*innen der beiden Sammlungen, des Museumsdokumentationsteams der Staatlichen Museen zu Berlin sowie zwei externe Personen teilnahmen. Zu Beginn des Workshops wurden die Fragestellungen der Forschungskooperation durch das Projektteam und die der Sammlungen durch die Kurator*innen vorgestellt. Daran anschließend wurden Kleingruppen gebildet, in denen Collagen (siehe Abb. unten) mithilfe von physischem Bildmaterial (Fotos) zu Objekten der Alten Nationalgalerie sowie des Museums Europäischer Kulturen erstellt wurden. Die Arbeit mit dem physischen Material hatte das Ziel, eine abstrakte Beschäftigung mit den Sammlungen zu erlauben, welche sich von der konkreten Idee eines Interfaces entfernt und sich auf die Schwerpunkte und Schnittstellen in den Sammlungen konzentriert (Chen, Dörk, and Dade-Robertson 2014; Dörk et al. 2020).
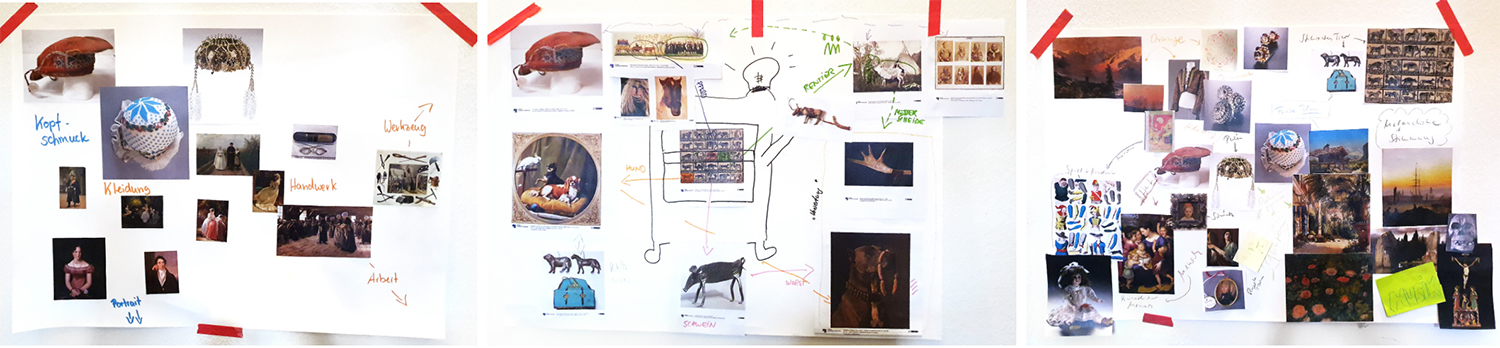
Die Auswertung der Collagen erfolgte in einer Gruppendiskussion und nach einem festen Schema: Zunächst interpretierten jene Teilnehmer*innen, welche die zu betrachtende Collage nicht erstellt hatten, was aus ihrer Sicht auf dieser zu sehen sei. Danach brachten die Ersteller*innen der entsprechenden Collage ihre eigene Perspektive auf die Bestände sowie die individuellen Intentionen hinter den Collagen ein. Darauf aufbauend wurden die Ziele und Schwerpunkte des Projekts sowie die Umsetzbarkeit in Bezug auf diverse Zielgruppen und die vorhandenen Datensätze der Sammlungen diskutiert und abgewogen.
Die erstellten Collagen folgten inhaltlich meist einer visuellen assoziativen Anordnung und Durchmischung der beiden Sammlungen; oft unter Zuhilfenahme von Schlagworten oder Kategorien. Dabei wurde durch die Teilnehmer*innen der explizite Wunsch geäußert, dass die Unterschiedlichkeit der Sammlungen in einer gemeinsamen Visualisierung zwar nicht aufgehoben, aber auch nicht durch eine getrennte Anordnung befördert werden sollte. Vielmehr sollte eine kreisförmige oder potentiell endlose Bewegung durch die Sammlungen im Sinne eines Flanierens möglich sein, wobei häufig von Assoziationsketten gesprochen wurde. Diese Bewegungen und Assoziationen sollten zum einen durch die Kunstwerke und Objekte selbst ausgelöst und zum anderen durch externe Inhalte wie Schlagworte unterstützt werden.
In der Abschlussdiskussion wurden intensive Überlegungen zu einer automatischen Bilderkennung und der Generierung von Schlagworten angestellt. Die damit einhergehenden Fragen waren: Wie könnten ähnliche Motive und Objekte zueinander gebracht und Bezüge zwischen ihnen hergestellt werden? Nach welchen Kriterien und durch wen (Algorithmus vs. Kuratierung) könnte eine Verschlagwortung vorgenommen werden? Es wurden auch individuelle Zugänge für unterschiedliche Zielgruppen und die Möglichkeit einer verbindenden Narration, die sich durch die Visualisierung ziehen könnte, diskutiert. Betont wurde, dass neben der freien Exploration der Sammlungen auch die Möglichkeit einer gezielten Suche angeboten werden sollte.
Sketching- und Prototyping-Prozess
Im weiteren Projektverlauf wurden zunächst die zu den ausgewählten Objekten vorhandenen Datensätze der beteiligten Sammlungen gesichtet, ihre Struktur untersucht und darauf aufbauend erste Ideen für mögliche Visualisierungs-Designs entwickelt. Um die konzeptionellen Vorüberlegungen und die Ideenfindung möglichst realistisch und eng an den tatsächlichen Visualisierungspotenzialen für die vorhandenen Daten entlang zu führen, wurde parallel mit der Datenaufbereitung (beispielsweise durch die Transformation vom LIDO-Format zum CSV-Format) und mit der Datenanalyse (beispielsweise durch die Verteilung von Dateiattributen und Fehlstellen) begonnen. Für die Datentransformation und Datenanalyse wurde auf die Nutzung von Jupyter Notebooks (Datenverarbeitung und -analyse) und Observable Notebooks (Datenanalyse und -visualisierung) zurückgegriffen. Jupyter und Observable Notebooks sind interaktive, webbasierte Dokumente, welche anschaulich Live-Coding und Datenanalyse ermöglichen, ergänzt durch narrative Textelemente zur Beschreibung des Codes. Durch das Zusammenbringen von Code und Dokumentation in einer gemeinsamen, linearen Ansicht bieten beide Werkzeuge gute Möglichkeiten, die Prozesse auch nachträglich zu vermitteln. Zusätzlich wurden in diesem Stadium bereits kleinere, web-basierte Visualisierungs-Prototypen entwickelt, um einen ersten visuellen Überblick über die Daten zu erhalten.
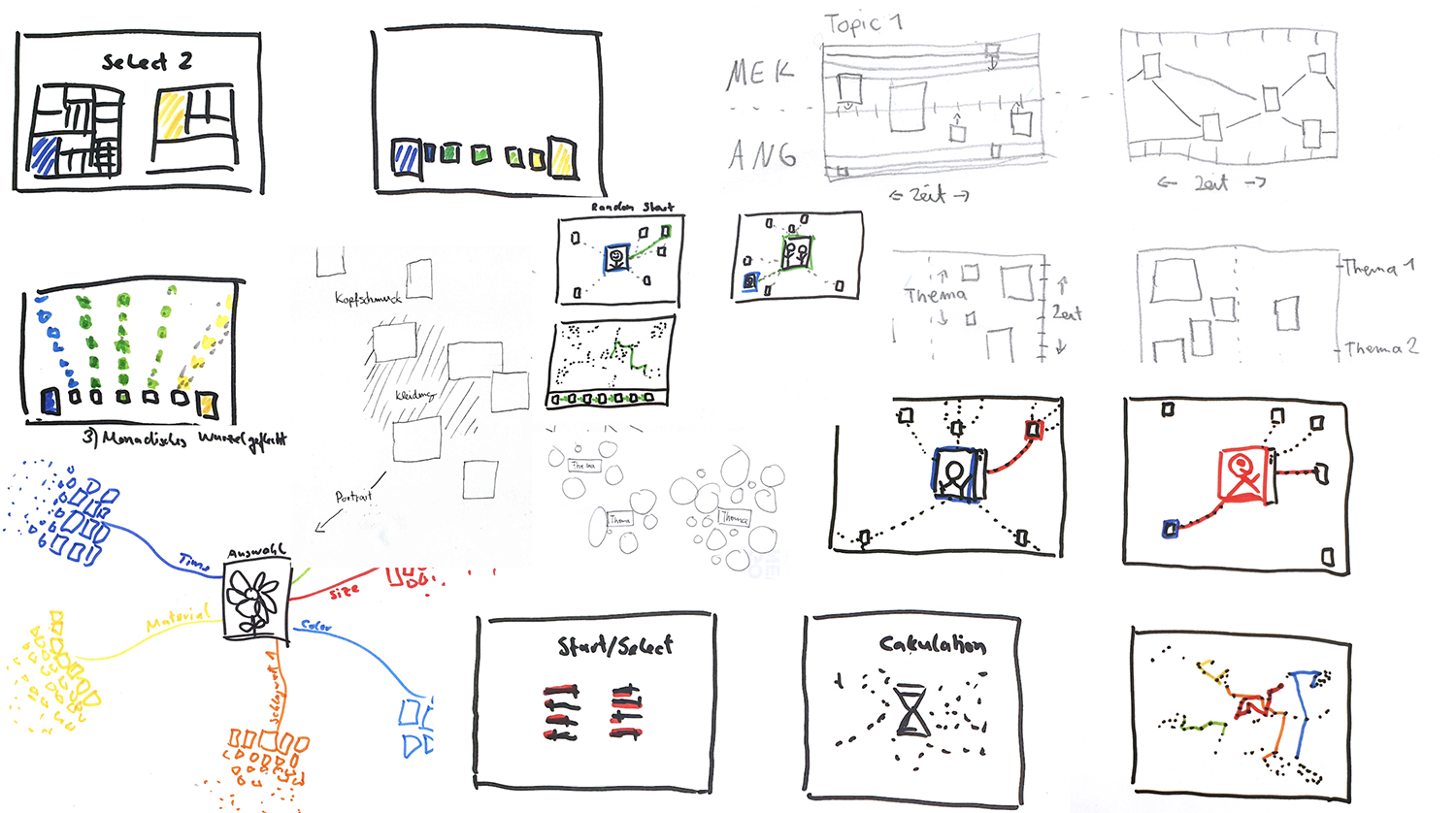
Aufgrund der Ergebnisse des Co-Design Workshops, der ersten Design-Ideen und der Projektbeschreibung waren zu diesem Zeitpunkt sowohl die visuelle Qualität der Kunstwerke und Objekte als auch mögliche assoziative Beziehungen zwischen den Objekten, insbesondere wenn sie aus unterschiedlichen Sammlungen stammen, als interessante Ausgangspunkte für die Visualisierung im Fokus. Durch die Datenexploration wurde bereits eine sehr heterogene Struktur innerhalb der Daten, beispielsweise in der zeitlichen Einordnung der Objekte oder der Länge und Qualität der Beschreibungstexte, deutlich. Es zeigte sich, dass die vorhandenen Datensätze für einen solchen vergleichenden Ansatz hätten intensiv inhaltlich nachbearbeitet werden müssen. So war die Verschlagwortung der Sammlungsobjekte im Museumsdokumentationssystem nicht ausreichend, um auf ihrer Grundlage eine assoziative Anordnung vorzunehmen, und eine Erweiterung der Schlagworte – wie im Workshop mehrfach erwähnt und als wünschenswert erachtet – wäre nur mit großem kuratorischen Aufwand möglich gewesen. Um unabhängig von den bereits bestehenden Schlagworten dennoch assoziative Relationen zwischen Sammlungsobjekten zu ermöglichen, wurden die Möglichkeiten des maschinellen Lernen zur algorithmischen Ähnlichkeitsanalyse zwischen Objekten und automatisierter Verschlagwortung herangezogen.
Im nächsten Schritt wurden die erstellten Ideen und Skizzen (siehe Abb. oben) mit allen Projektbeteiligten geteilt und eine Auswahl getroffen. Im ersten Ergebnis sollte für die Visualisierung von einer Gesamtansicht oder einem zufällig ausgewählten Objekt ausgegangen werden, von dem aus die Erkundung individueller Ähnlichkeitspfade ermöglicht wird. Daran anschließend wurden erste Datenexperimente durchgeführt, um die verschiedenen Möglichkeiten einer auf maschinellem Lernen basierenden Ähnlichkeitsanalyse auszuloten. Maschinelles Lernen ermöglicht auf der Grundlage von komplexen und umfangreichen Daten viele verschiedene Formen der Ähnlichkeitsanalyse. So lässt sich Ähnlichkeit beispielsweise anhand von Bilddaten, Metadaten, Beschreibungstexten oder einer Mischung aus mehreren dieser Datendimensionen ermitteln. Die Entscheidungsgrundlage dafür, auf welche Weise die Ähnlichkeitsanalyse innerhalb dieses Projekts durchgeführt werden sollte, war, möglichst plausible und nachvollziehbare Ähnlichkeiten herzustellen (beispielsweise über die Bildinhalte), inhaltlich bedingte Ähnlichkeiten einzubeziehen und Sammlungsobjekte unterschiedlicher Sammlungen zusammenzubringen. Die prototypische Berechnung und Darstellung mehrerer Konfigurationen ergab, dass unter der Berücksichtigung dieser Ziele die Mischung einer kombinierten Ähnlichkeitsanalyse der Bildähnlichkeit und Titelähnlichkeit die vielversprechendsten Ergebnisse liefern würde.
Um zu einer Entscheidung für den umzusetzenden Entwurf zu gelangen, wurde zum Ende dieser Phase ein Feedbackgespräch mit den beteiligten Kurator*innen der Sammlungen geführt, um die möglichen Designs und die endgültige Auswahl der Ähnlichkeitsanalyse zu besprechen. Die in diesem Zusammenhang gezeigten, ersten konkreten Entwürfe der Startansicht wurden von den Beteiligten positiv aufgenommen. Seitens der Kurator*innen wurde darauf hingewiesen, dass eine detaillierte Erklärung der Startansicht sowie der Ähnlichkeitsanordnung nötig sei, um den Einstieg für die Nutzer*innen zu erleichtern. Durch das Projektteam wurden daraufhin einleitende, prominent platzierte Schlagworte für die Startansicht vorgeschlagen und im Folgenden die Möglichkeiten einer automatischen Verschlagwortung diskutiert und mithilfe eines vortrainierten Modells (Beyer et al. 2020) getestet. Da der verwendete Algorithmus auf der Grundlage der vorhandenen Abbildungen teilweise keine zufriedenstellenden und zu unspezifische Schlagworte aggregierte (so wurde beispielsweise der Fokus auf den Rahmen eines Kunstwerks gelegt, da dieser bildlich dominanter als der eigentliche Inhalt des Kunstwerks hervortritt) oder wertende, beziehungsweise keine prägnanten Aussagen über die Objekte traf (beispielsweise Kleptomane oder Schnurrbart als Zuordnung zu Porträts), wurde dieser in Rücksprache mit den Kurator*innen für dieses Projekt ausgeschlossen. Um eine Lösung zu finden, wurden in Zusammenarbeit mit den Kurator*innen Schlagworte erstellt. Hierzu wurden inhaltliche Cluster in der Startansicht ausgemacht und mögliche Schlagworte aus der Logik der Sammlungen heraus diskutiert und festgehalten.
Ergebnisse
Das aus den Vorüberlegungen entstandene Visualisierungskonzept greift zum einen den Grundsatz „Overview First, Zoom and Filter, then Details on Demand“ (Shneiderman 1996), teilweise aber auch Ansätze „monadische[r]“ Ansichten (Dörk, Comber, and Dade-Robertson 2014) auf, welche die Gesamtheit von Sammlungen aus einer von individuellen Objekten ausgehenden Perspektive heraus betrachten. Die entstandene Visualisierung wurde als web-basierte Anwendung mithilfe des JavaScript-Frameworks Svelte, der Softwarebibliothek für Datenvisualisierung D3.js und der WebGL Rendering Library PixiJS entwickelt. Die Visualisierung besteht dabei aus zwei Teilen (siehe Abb. unten), welche fließend miteinander verwoben sind und Bewegungen zwischen diesen ermöglichen:
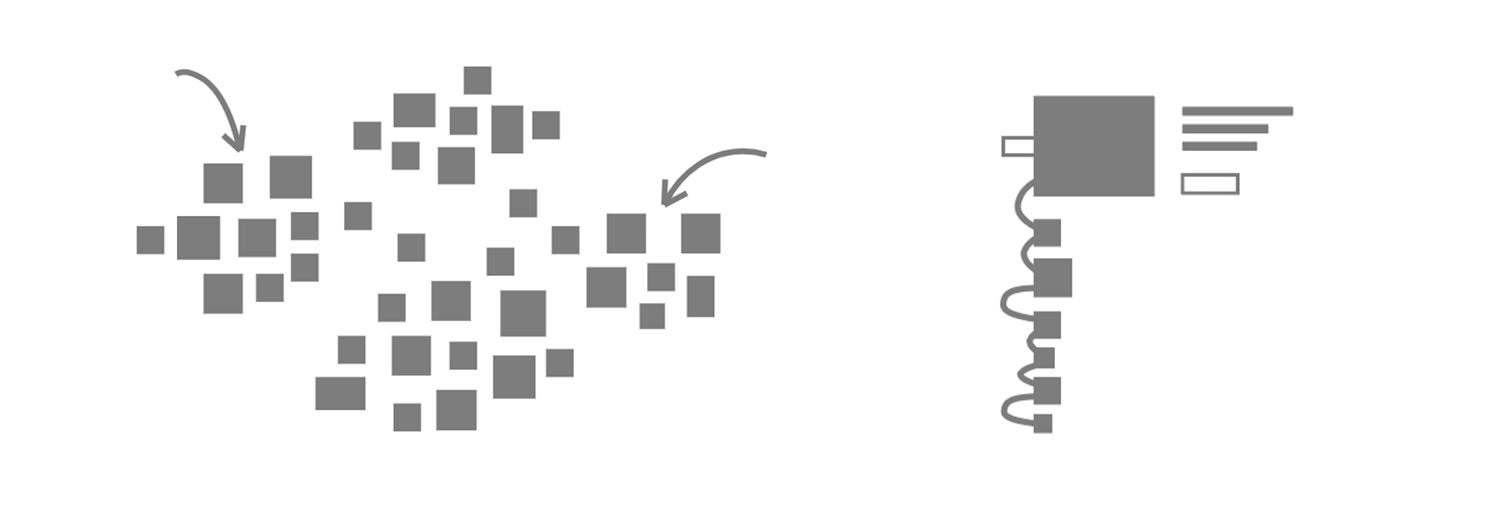
- Die Wolken-Ansicht ist eine globale Übersicht über alle Objekte, die mithilfe eines Ähnlichkeitsalgorithmus nach Bild- und Titelähnlichkeit anordnet.
- Die Pfad-Ansicht zeigt eine Liste, die von einem ausgewählten Objekt ausgehend und lokal auf Bild- und Titelähnlichkeit basierend, andere Objekte der Sammlungen nach absteigender Ähnlichkeit auflistet.
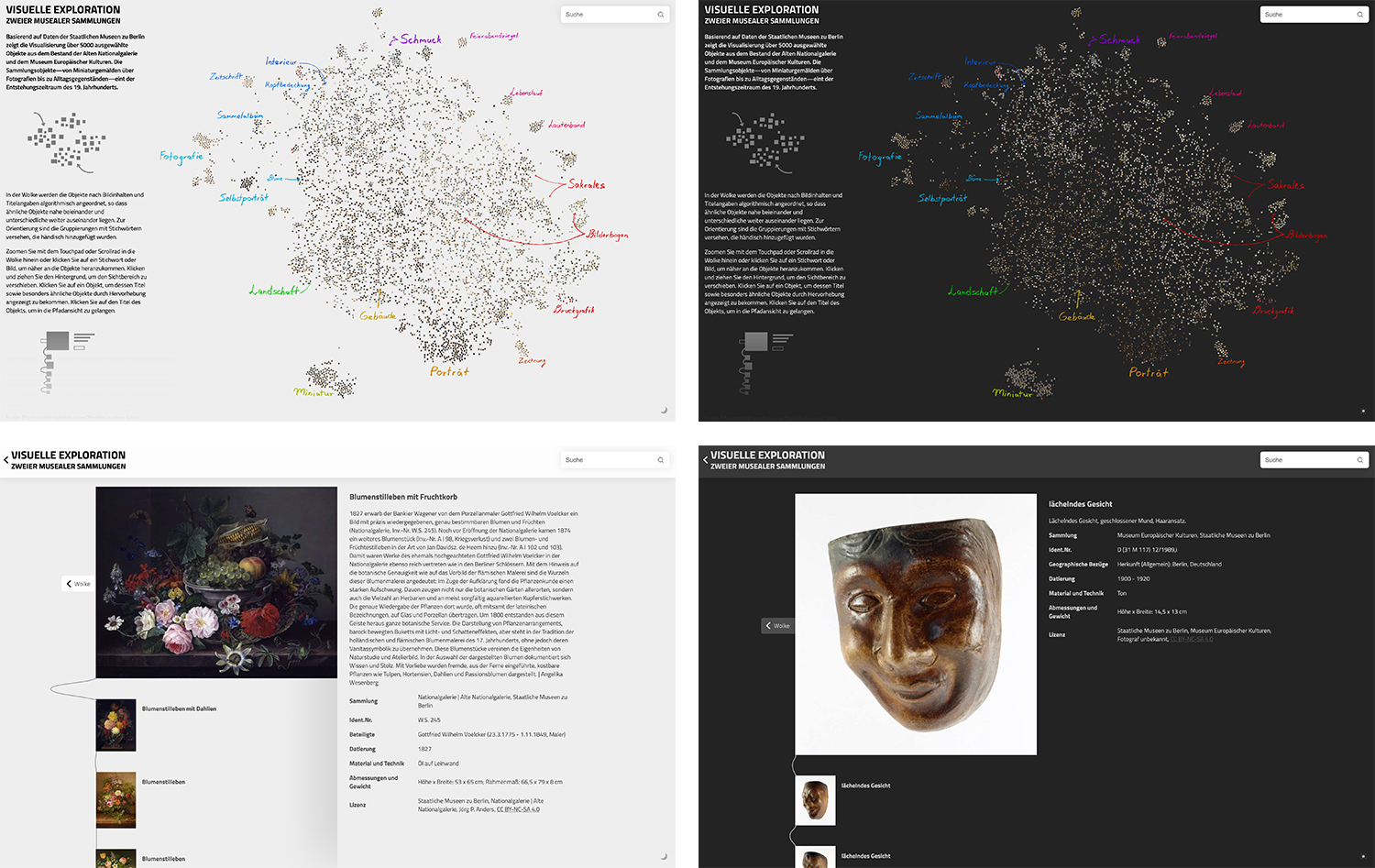
Zusätzlich kann die Visualisierung, abhängig von im Betriebssystem vorgenommenen Voreinstellungen oder durch Wechsel über ein kleines Sonnen-/Mond-Icon, in einem hellen und einem dunklen Layout angezeigt werden (siehe Abb. oben).
Die Wolken-Ansicht
In der Wolken-Ansicht (siehe Abb. unten) werden die Objekte algorithmisch so angeordnet, dass ähnliche Objekte näher beieinander und weniger ähnliche weiter auseinander liegen. Die Anordnung erfolgt dabei nach der Bild- und Titelähnlichkeit: Der Algorithmus vergleicht die visuellen Inhalte der Objektabbildungen und ihre textlichen Titel und ordnet sie in der Visualisierung so an, dass ähnliche Objekte nahe beieinander liegen. Dadurch bilden sich in der Visualisierung Inseln (Cluster) aus den Objekten, welche sich in den Kategorien Abbildung und Titel besonders ähnlich sind. Eine mögliche Nähe zwischen einzelnen Clustern verweist jedoch nicht zwingend auf eine Ähnlichkeit dieser Cluster.
Technisch basiert diese Anordnung auf der UMAP Technik zur Reduktion multidimensionaler Daten, welche die Multidimensionalität anhand von lokalen und globalen Ähnlichkeiten zwischen Objekten auf einen zweidimensionalen Raum abbildet (McInnes, Healy, and Melville 2018). Unter Dimensionalitätsreduktion versteht man hierbei die Vereinfachung mehrerer Datenaspekte (beispielsweise Titel, Datierung, Abmessung, Gewicht) auf eine kleinere (aber abstrakte) Dimensionsmenge (beispielsweise x, y), um zum Beispiel komplexe Daten auf einer zweidimensionalen Fläche anzuordnen. Das übergeordnete Ziel dieser Technik ist es, ähnliche Objekte nah zueinander zu platzieren.
Die Datendimensionen, die in der hier beschriebenen Anwendung in den Algorithmus einfließen, basieren wiederum auf zwei vorausgegangen Dimensionalitätsreduktionen. Unter Nutzung des maschinellen Lernsystems TensorFlow (Abadi et al. 2016) werden wesentliche Merkmale aus den Bild- und Textdaten extrahiert. Diese Merkmalsextraktion führt dazu, dass die Daten (zum Beispiel alle Pixel eines Bildes) durch maschinelles Lernen in einer Weise reduziert werden, dass sie durch neu generierte Datenwerte besondere Unterscheidungsmerkmale der Ausgangsdaten repräsentieren. Für die Merkmalsexktraktion bei den Titeldaten wurde hier Universal Sentence Encoder Multilingual (Yang et al. 2019) verwendet und für die Merkmalsextraktion der Bilddaten Big Transfer (Kolesnikov et al. 2020). Anschließend wurden die resultierenden Merkmale beider Verfahren normalisiert und über die zuvor bereits genannte weitere Dimensionalitätsreduktion (UMAP) in einer einzelnen Projektion kombiniert und auf zwei Datendimensionen (x- und y-Achse) zur Visualisierung abgebildet. Diese generierten x- und y-Werte werden abschließend genutzt, um die Thumbnails von den Sammlungsobjekten in einer Übersichtsansicht zu arrangieren.
Im Verlauf des Projekts wurden mehrfach Feedbackgespräche mit allen Projektbeteiligten und den Kurator*innen der Sammlung geführt, um die verschiedenen Ideen und Ergebnisse der algorithmischen Anordnung zu besprechen. Einer Kombination aus Bild- und Titelähnlichkeit wurden Einzelansichten, die beispielsweise nur auf Bildähnlichkeit beruhen, vorgezogen, da so auch inhaltlich-thematische Verbindungen zwischen den verschiedenen Sammlungen sichtbar werden könnten. Im Sinne des iterativen Prozesses wurden auch die Workshop-Ergebnisse immer wieder konsultiert und die dort entstandenen Objekt-Zusammenführungen mit den durch den Algorithmus generierten verglichen. Da ein Versuch mit maschinell erzeugten Schlagworten nicht glückte, wurden in einem weiteren Workshop, gemeinsam mit den Kurator*innen, die innerhalb der Visualisierung entstehenden Cluster durchgegangen und hervorstechende Gruppen mit Schlagwörtern versehen, die händisch annotiert wurden. Projektionen von multidimensionalen Skalierungen werden häufig annotiert, um Anordnungen solcher Algorithmen und Dimensionalitätsreduktionen für die Nutzer*innen nachvollziehbarer zu machen (z.B. Stefaner 2018, Vane 2018). Die Annotationen wurden handschriftlich gestaltet, um den Gegensatz zwischen der algorithmischen Anordnung und der Identifizierung und Benennung der Cluster durch die Kurator*innen aufzugreifen.

Während eine globale Ähnlichkeitsdarstellung in der Lage ist, übergreifende Strukturen zu vermitteln, handelt es sich bei dieser Form der Darstellung dennoch um einen Kompromiss aufgrund einer Reduktion der Daten, die in der Darstellung auch fehlerhafte oder fehlleitende Nähen und Distanzen zwischen einzelnen Objekten erzeugen kann (Stahnke et al. 2016). So ist eine Nähe zwischen einzelnen Objekten zwar ein Indiz für Ähnlichkeit, schließt aber nicht aus, dass andere, weiter entfernte Objekte innerhalb der Wolke ebenfalls größere Ähnlichkeiten aufweisen oder zu Objekten in direkter Nähe geringfügige Ähnlichkeiten bestehen. Um individuelle Ähnlichkeiten zwischen Objekten besser darzustellen, wurden zusätzlich zur globalen Ähnlichkeitsansicht lokale, von einem einzelnen Objekt oder Suchbegriff ausgehende, Ähnlichkeitsansichten eingeführt. So führt eine Eingabe in das Suchfeld beispielsweise zur Anzeige von weiteren, häufig über die gesamte Wolke verteilten Objekten (siehe Abb. oben), die in ihren Metadaten den eingegebenen Suchbegriff enthält.
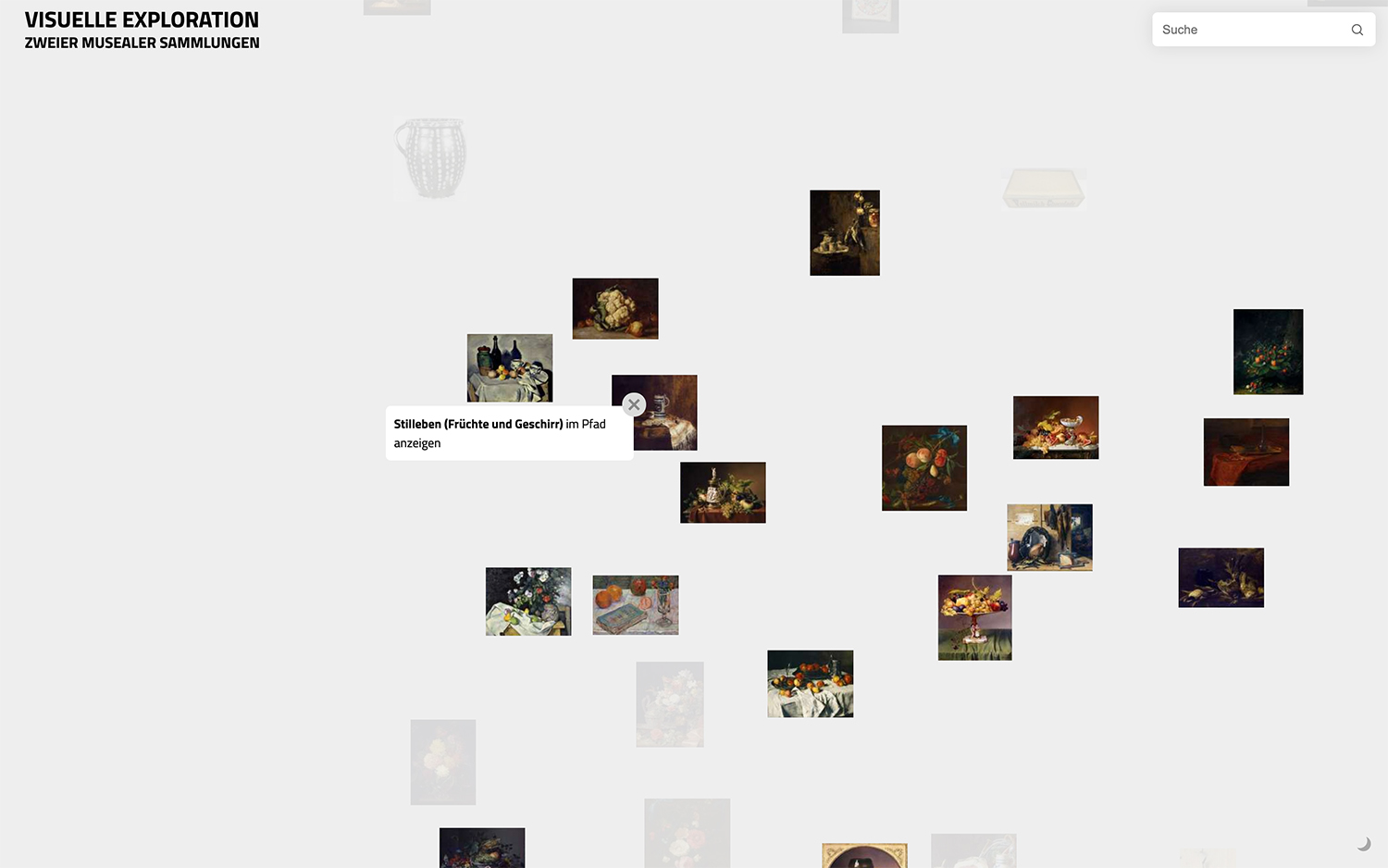
Über eine Vergrößerungsfunktion gelangen die Nutzer*innen von der Wolken-Ansicht in eine detaillierte Bildansicht. Ebenso können Schlagwörter oder Bilder angeklickt werden, um diese Zoomstufe zu erreichen (siehe Abb. oben). Mittels Klick und Ziehen nach links oder rechs kann der Sichtbereich verschoben oder ein Objekt ausgewählt werden. Durch einen Klick auf ein Objekt in der Wolke werden zunächst besonders ähnliche Objekte in der Wolke hervorgehoben. Ein weiterer Klick auf den Titel des Objekts startet eine Übergangsanimation, bei der die ähnlichen Objekte in der Wolke hervorgehoben und zu einer Liste animiert werden, welche in der Pfad-Ansicht resultiert.
Die Pfad-Ansicht
In der Pfad-Ansicht werden Objekte in einer Liste angezeigt, die einem ausgewählten Objekt in Titel und Bild ähneln oder einer Suchanfrage entsprechen. Die Ausschläge des Fadens zwischen den Objekten zeigen den Grad der Ähnlichkeit in absteigender Ausprägung: Je größer der Ausschlag des Fadens, desto weiter entfernt und somit unähnlicher ist das nächste Objekt zum ausgewählten oder vorhergehenden Objekt. Zusätzlich zu dieser Darstellung werden die Werte der Ähnlichkeitsberechnung (beispielsweise 90% Ähnlichkeit zur Auswahl) in den Metadaten angezeigt, um die Nachvollziehbarkeit der Anordnung zu verbessern.
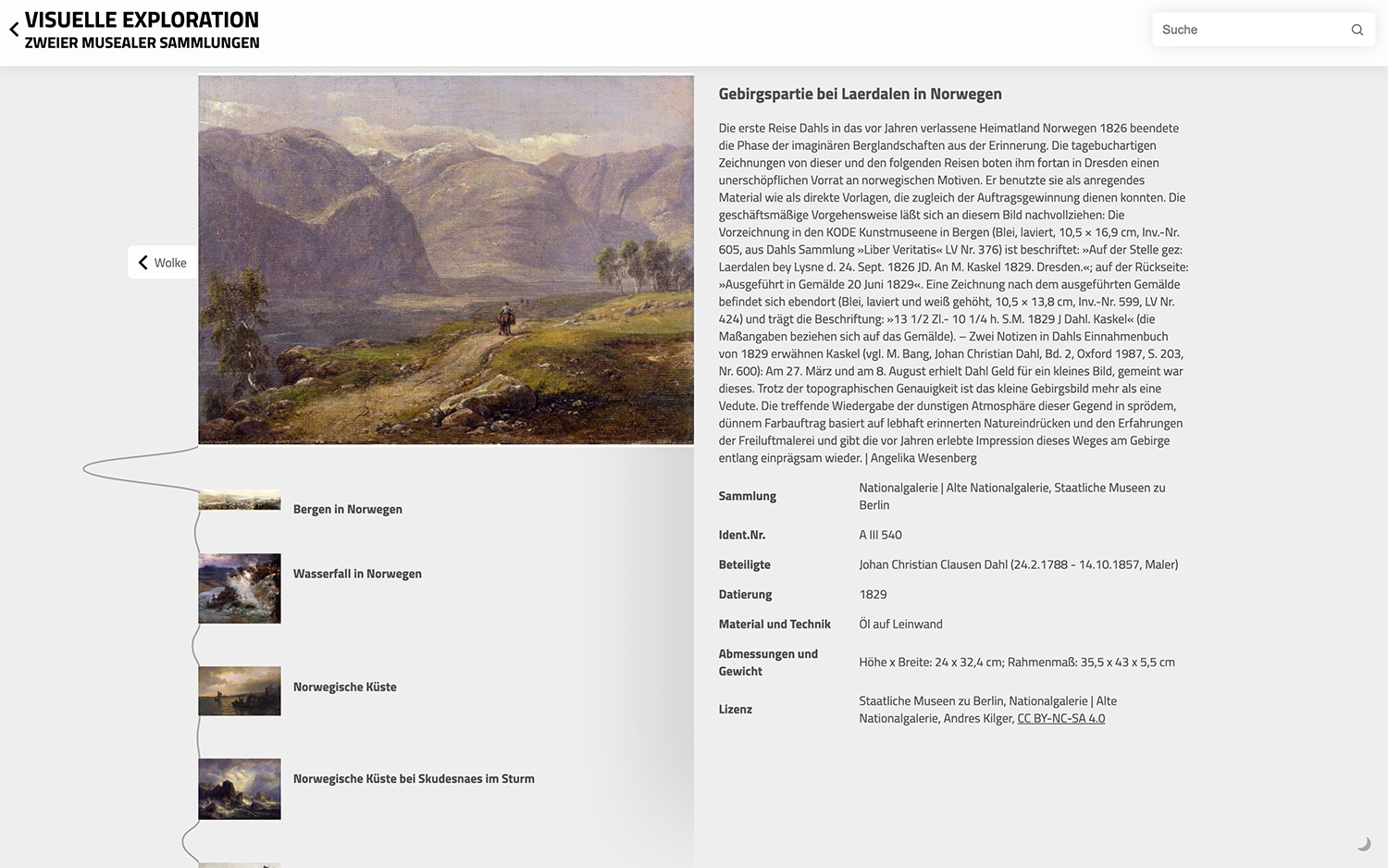
Ein Klick auf ein Objekt führt, unter Beibehaltung der Anordnung, zunächst zum Anzeigen der Metadaten des entsprechenden Objekts (siehe Abb. oben). Mit einem weiteren Klick auf das Bild wird eine größere Ansicht des Bildes in hoher Auflösung möglich. Mittels des Buttons an der linken Seite des Bildes oder über einen Klick auf den Titel der Anwendung beziehungsweise über die Zurück-Taste des Browsers kann zurück zur Wolke navigiert werden. Dort wird die entsprechende Objektauswahl beibehalten, sodass man sich in der Wolke immer an der Stelle des Objekts befindet, welches man zuletzt in der Pfad-Ansicht betrachtet hat.
Technisch basiert die Anordnung der Pfad-Ansicht, ebenso wie die Anordnung der Wolken-Ansicht, auf den vorangegangenen Ähnlichkeitsanalysen. Im Gegensatz zur globalen Ähnlichkeit in der Wolken-Ansicht werden die lokalen Ähnlichkeiten (die für jede Auswahl individuellen Ähnlichkeitsketten) durch Berechnung eines Ähnlichkeitswertes zwischen dem ausgewählten Objekt und je allen anderen Objekten bestimmt (das Skalarprodukt des Vektors des ausgewählten Objekts und des Vektors der jeweils anderen Objekte berechnet). Aus diesen berechneten Werten wird ein Prozentwert und ein Ranking erstellt. 100% Ähnlichkeit ist in diesem Fall der Maximalwert und würde einem identischen Objekt entsprechen. Absteigend nach Ähnlichkeit werden so die anderen Objekte im Pfad bis zu einer Ähnlichkeit von mindestens 25% angezeigt; Objekte mit einem geringeren Ähnlichkeitswert als 25% werden dagegen nicht angezeigt, mit dem Grund, dass mit abnehmender Ähnlichkeit die Anordnung zunehmend zufällig wirkt.
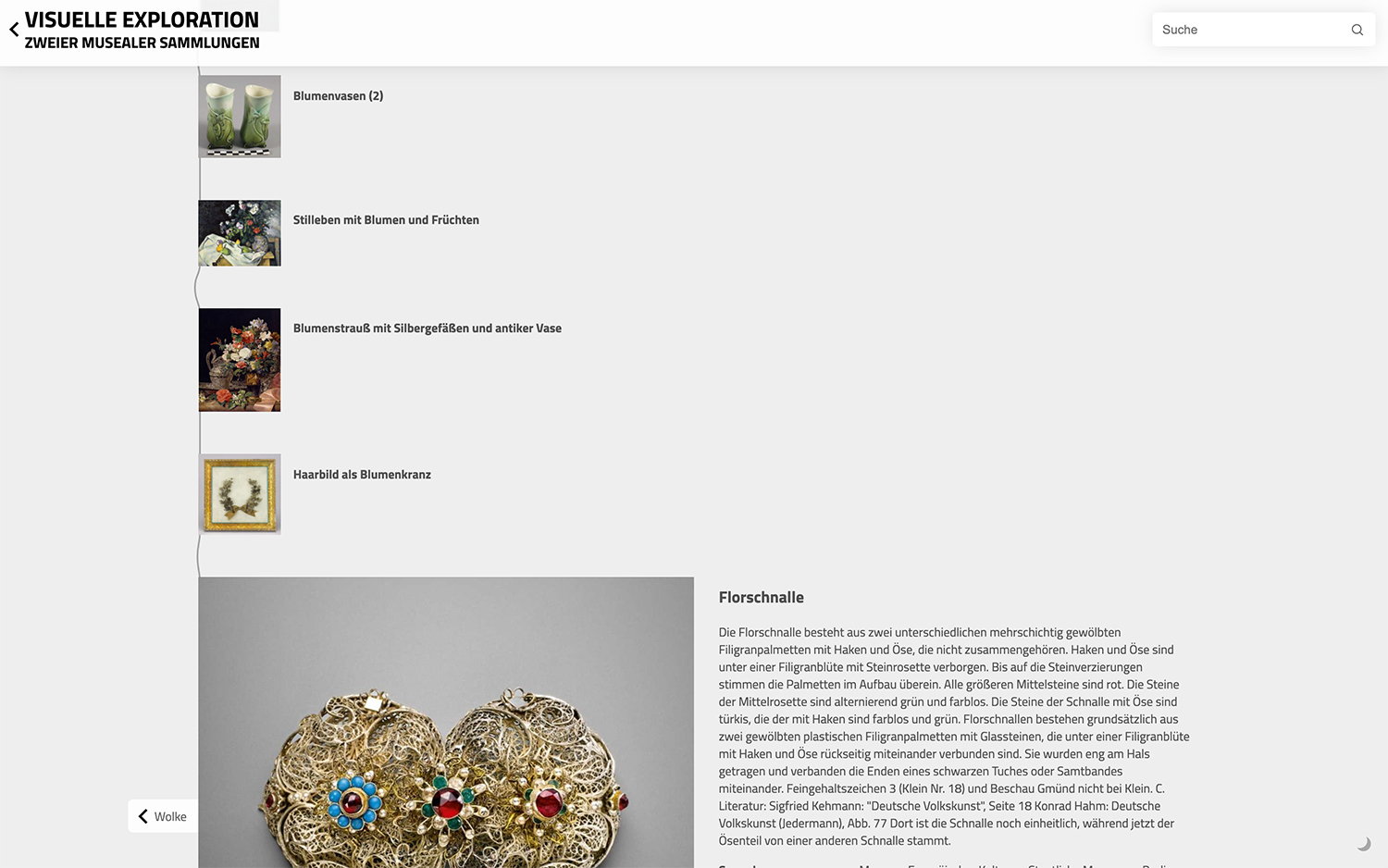
Die Anordnung nach Bild- und Titelähnlichkeit führt hier zu einer assoziativen Verknüpfung der Werke und der Objekte. Wenn das gleiche Wort beispielsweise immer wieder vorkommt, können Ähnlichkeiten in der Pfad-Ansicht anhand der Titel nachvollzogen werden. Eine assoziative Kette zeigt so, zum Beispiel vom Titelwort Blume ausgehend, Werke die das Wort Blume(n) im Titel tragen oder auf denen Blumen zu sehen sind. So werden Schmuckstücke mit floralem Muster mit Blumenvasen und Stillleben kombiniert (siehe Abb. oben). Folgen Nutzer*innen den Objekten in der Liste anhand der Titel- und Bildinhalte, zeigt sich, dass die Ähnlichkeiten zwischen den Objekten abnimmt. Mithilfe des unter den Metadaten des ausgewählten Objekts angezeigten Buttons Zeige ähnliche Objekte als Pfad kann, ausgehend von diesem Objekt, ein neuer Ähnlichkeitspfad angezeigt werden. Bei einer Suche und Auswahl der Ergebnisse als Liste werden die Objekte in der Pfad-Ansicht hingegen ungeordnet und ohne Ähnlichkeits-Faden angezeigt. Die Suche bietet dabei statt einer Ähnlichkeitsanalyse auf Bild- und Titelähnlichkeit eine Volltextsuche über die Metadaten-Felder an (ohne Beschreibung), so dass beispielsweise auch Werke einzelner Künstler*innen gefunden werden können.
Evaluation
Im Zuge des iterativen Entwicklungsprozesses wurden die Fortschritte über den Projektzeitraum regelmäßig mit dem gesamten Team besprochen. Eventuelle Änderungswünsche konnten so direkt umgesetzt und Feedback von den Kurator*innen der Sammlungen eingeholt werden, um diese als zukünftige Nutzer*innen, aber auch Expert*innen für ihre Bestände, einzubeziehen. Insbesondere das Experiment mit maschinell erzeugten Schlagworten erzeugte bei den Kurator*innen großes Interesse, da eine vergleichbare, maschinelle Analyse der Sammlungen noch nie durchgeführt worden war. Letztlich wurde sich innerhalb des Projekts aufgrund der schwankenden Ergebnisse dieses Experiments jedoch für eine händische Annotation der Wolken-Ansicht entschieden und hierfür ein erneuter kleiner Workshop mit Feedback-Runde durchgeführt.
Zusätzlich wurde der Prototyp in der finalen Projektphase von verschiedenen Zielgruppen getestet. Dabei lag das Erkenntnisinteresse in zwei Bereichen: Zum einen sollte die Usability (also die Nutzer*innenfreundlichkeit) getestet werden, um letzte Änderungen am Prototyp vornehmen zu können, zum anderen sollten die zu Beginn des Projekts definierten Ziele und Forschungsfragen überprüft werden. Als Methode wurde hierfür eine qualitative Evaluation mittels einer Think-Aloud Studie gewählt (vgl. Klaus 2010). Dafür wurde den Teilnehmer*innen der Zugang zum Prototyp ermöglicht, den sie dann mithilfe ihrer eigenen Endgeräte erkunden sollten. Während der Interaktion wurden sie gebeten, laut auszusprechen, was sie dabei sehen, ausführen, erwarten oder denken. Aufgrund der Einschränkungen durch die Covid19-Pandemie wurde die Studie über ein Videokonferenzsystem durchgeführt, über das die Teilnehmer*innen ihren Bildschirm mit den Projektbeteiligten teilten. Zur besseren Nachvollziehbarkeit wurden die Interaktionen per Video aufgezeichnet. Aus diesen Videos wurden anonymisierte wörtliche Transkripte der einzelnen Testsitzungen erstellt, um daraus exemplarische Zitate für die Auswertung zu verwenden.
Die Evaluation teilte sich entlang verschiedener Nutzer*innengruppen in zwei Phasen auf:
Zunächst wurden drei Personen befragt, die sich professionell mit Datenvisualisierungen beschäftigen. Es folgten drei Personen, die sich hinsichtlich der Nutzung von Datenvisualisierungen und dem musealen Bereich eher als Noviz*innen einordneten sowie zwei Personen, welche sich professionell mit digitalen Museumsangeboten beschäftigen. Der Grad des entsprechenden Vorwissens wurde mittels eines Fragebogens erfragt. Während diese ersten Testings eher die freie Exploration mit dem Prototyp fokussierten, wurden in einer zweiten Evaluationsphase sechs Museumsmitarbeiter*innen der Staatlichen Museen zu Berlin gezielte Aufgaben zur Nutzung des Prototyps gestellt, um einen konkreten (fiktiven) Anwendungsfall für diese Nutzer*innengruppe zu schaffen.
Erste Evaluationsphase
Die erste Evaluationsphase zeigte, dass ein assoziatives Bewegen durch die Sammlungen nach einem selbst gewählten oder gegebenen Interesse in den meisten Fällen gut funktionierte und von vielen Testpersonen als positiv wahrgenommen wurde. Besonders die Schlagworte wurden als Einstieg intensiv genutzt und als inspirative Kraft gelobt. Ebenso wurden die Wolken-Ansicht und die Pfad-Ansicht genutzt, um durch die Objekte zu stöbern und die Möglichkeit, überraschende Entdeckungen – entsprechend des häufig gesetzten Ziels von digitalen Sammlungsvisualisierungen zur Förderung von Serendipität (Thudt, Hinrichs, and Carpendale 2012) – zu machen, gelobt:
„Ich gehe von einem bekannten Konzept aus, sehe aber dann noch ganz andere Möglichkeiten. […] Spannend natürlich, weil man dann plötzlich Zusammenhänge sieht und auf Dinge stößt, die man nicht unbedingt sonst in Zusammenhänge gestellt hätte.“ [Interview Nr. 14, S. 8] und „I really like the fact that as much as I go through things, I like to keep exploring, like it’s very serendipitous I’d say.“ [Interview Nr. 2, S. 5].
Auch die Personen, die sich professionell mit digitalen Museumsangeboten beschäftigen, hoben hervor, dass die assoziative Bewegung von Objekt zu Objekt für sie zu neuen Erkenntnissen führe und somit als Ergänzung oder Abwechslung zu klassischen Recherche-Plattformen oder für eine thematische Annäherung genutzt werden könnte:
„In der Regel suche ich etwas ganz Konkretes oder Inspiration ‒ und oft geht dann beides zusammen. Ich finde, es ist ein Mehrwert, hier inspiriert zu werden.“ [Interview Nr. 5, S. 5].
„Das ist etwas, worin man sich gut verlieren kann ‒ vielleicht nicht unbedingt für die Recherche, aber zum Zeitvertreib perfekt.“ [Interview Nr. 4, S. 4].
Die Ähnlichkeits-Anordnung in der Wolke sowie in der Pfad-Ansicht konnten von den meisten Teilnehmenden nicht komplett erschlossen werden. Hier konnte der Einführungstext, welcher oft jedoch als zu lang wahrgenommen wurde, sowie ein Mouseover-Effekt mit einer Erklärung der Ähnlichkeits-Ausschläge in der Pfad-Ansicht für die meisten Personen Abhilfe schaffen. Insbesondere die Pfad-Ansicht stellte jedoch eine interpretative Herausforderung für die Teilnehmenden dar. In der Wolke boten die Schlagworte eine gute Orientierung für die Anordnung, auch wenn sie von etwa der Hälfte der Teilnehmenden für übergeordnete Kategorien gehalten wurden, welche dann auch in der Pfad-Ansicht als Kriterium der Anordnung erwartet wurden. Zumeist erfolgte jedoch der Versuch, eine Ähnlichkeit in der Pfad-Ansicht mittels eines visuellen Vergleichs und eines Vergleichs der Titel und Beschreibungstexte vorzunehmen, auch wenn die resultierenden Interpretationen nicht immer zutreffend waren. Der Button Zeige ähnliche Objekte als Pfad wurde hingegen überwiegend gut verstanden und in drei Fällen auch direkt mit der Anordnung und Hervorhebung ähnlicher Objekte in der Wolke in Verbindung gebracht. Auch wenn die algorithmische Anordnung insgesamt nicht immer nachvollziehbar war, wirkten die Teilnehmenden grundsätzlich interessiert an ihrer Neuartigkeit und den aufgeworfenen Fragen:
„Es ist auf alle Fälle anders als ein Museumsbesuch, weil man mehr auf die Technik fokussiert ist. Aber es ist interessant, den Algorithmus nachzuvollziehen oder auch zu hinterfragen, wie das funktioniert.“ [Interview Nr. 7, S. 1]
Im Zuge der Evaluation wurden schließlich Verbesserungen von UX-Aspekten vorgenommen, um etwa die Navigation zwischen Wolken- und Pfad-Ansicht zu vereinfachen. Auf einige Punkte, die wiederholt in den Testings vorkamen, konnte jedoch nicht mehr eingegangen werden, da sie entweder einen zu großen Arbeitsaufwand bedeutet hätten oder schlicht nicht umsetzbar waren. So wurde von etwa der Hälfte der Testpersonen gewünscht, eine noch höhere Auflösung der Abbildungen zur Verfügung zu haben und in der Wolke näher heranzoomen zu können, was aus Performance-Gründen und dem zugrundeliegenden Daten-Export nicht möglich war. Des Weiteren wurde der transformative Übergang von der Wolken- in die Pfad-Ansicht von einer Mehrzahl der Testpersonen als verwirrend wahrgenommen, da statt eines Zoom-Out und folgendem Zoom-In ein direkter Zoom-In erwartet wurde. Dieser Übergang, der eigentlich die Nachvollziehbarkeit der Anordnung der Objekte in der Pfad-Ansicht gewährleisten sollte, wurde jedoch nach Verwirrung beim ersten Vorkommen häufig in darauffolgenden Wiederholungen von den Teilnehmenden besser nachvollzogen, sodass vorab von einer Änderung der Animation abgesehen wurde.
Zweite Evaluationsphase
In der zweiten Phase des Testings wurden Mitarbeiter*innen der Staatlichen Museen zu Berlin einbezogen, die seitens des Projektteams Visitor Journey neu gedacht, museum4punkt0 als wichtige Zielgruppe definiert wurden. Als potenzielle Nutzer*innen der Anwendung sollten sie die Inhalte perspektivisch kollaborativ mitgestalten. Ob die Nutzer*innen die Ähnlichkeiten und Beziehungen in der Wolken- und Pfad-Ansicht erkennen und eigenständig erschließen können sowie worauf diese basieren, bildeten die Ausgangsfragen für das Testing. Darauf aufbauend sollten die (1) Nutzer*innenführung und (2) die Funktionen des Prototyps untersucht werden. Konkrete Untersuchungsfragen waren:
- Wie navigieren die Proband*innen in der Wolken-Ansicht?
- Wie empfinden die Proband*innen das Zoomen in der Wolken-Ansicht?
- Wie empfinden die Proband*innen den Wechsel zwischen Wolken-Ansicht und Pfad-Ansicht und umgekehrt?
- Erkennen die Proband*innen die verschiedenen Buttons und die Suchfunktion?
Für die Betrachtung des zweiten Untersuchungsschwerpunkts war das eingangs formulierte Ziel der Forschungskooperation, dass die Sammlungen der Staatlichen Museen zu Berlin in ihrer heterogenen Zusammensetzung erfasst und die verschiedenen Objektarten, Fachdisziplinen und Spezifika im Ganzen und im Detail visualisiert werden sollten, die Grundlage. Während des Testings sollte ermittelt werden, inwiefern die Proband*innen die Ähnlichkeiten und Beziehungen der Objekte auf Basis der Abbildungen und Titel erkennen. Darauf aufbauend sollte geprüft werden, ob die Proband*innen die Beziehungen in einen Deutungszusammenhang setzen:
- Erkennen die Proband*innen die Einordnung der Beziehungen zwischen den Objekten in der Wolken-Ansicht?
- Versuchen die Proband*innen zu deuten worauf die Beziehungen basieren?
- Erkennen die Proband*innen die Ähnlichkeiten zwischen den Objekten in der Pfad-Ansicht?
- Versuchen die Proband*innen zu deuten worauf die Ähnlichkeiten basieren?
- Gehen die Proband*innen davon aus, dass die Ähnlichkeiten in der Pfad-Ansicht einen Zusammenhang zu den Beziehungen in der Wolken-Ansicht haben?
- Welche möglichen Nutzungsszenarien der Anwendung werden von den Proband*innen genannt?
Von diesen Fragestellungen ausgehend, standen folgende Annahmen im Vordergrund:
- Die Proband*innen verwenden zur Erfüllung der Aufgabe die Schlagworte oder die Volltextsuche.
- Die Proband*innen werden die Schlagworte und Beziehungen in der Wolken-Ansicht nur bedingt erschließen können.
- Die Proband*innen werden den Faden und seine Ausschläge in der Pfad-Ansicht nur bedingt erkennen und zuordnen können.
Auswahl der Proband*innen und Aufgaben
Durch die sechs wissenschaftlichen Mitarbeiter*innen der Staatlichen Museen zu Berlin wurden drei verschiedene Fachdisziplinen – Archäologie, Kunstgeschichte und Ethnologie – repräsentiert. Für die Auswahl wurde angenommen, dass sowohl disziplinäre Aspekte in das Testing einfließen, als auch unterschiedliche Grade der Vertrautheit mit ähnlichen Anwendungen bei den Proband*innen vorhanden sind. Für die Durchführung wurde allen Teilnehmer*innen eine separate Aufgabe gestellt, bei denen es weder um fachwissenschaftliche Richtigkeit, noch um eine genaue Lösungsfindung ging. Vielmehr sollten sie den Teilnehmenden eine Hilfestellung zur Annäherung an den Prototyp geben. Berücksichtigt man die Gründe für die Nutzung verschiedener Fachdatenbanken und Online-Sammlungen durch Museumsmitarbeiter*innen, sind ihre eigenen beruflichen Praktiken und Recherchefragen eine wichtige Motivation. Die Aufgaben zielten daher auf eine Suchanfrage ab oder verfolgten eine offene themengebundene Umsetzung, wie beispielsweise:
- Sie setzen sich näher mit dem Thema zur kunsthistorischen Bedeutung von Pflanzen und Blumen auseinander und suchen passende Objekte. ‒ Intendiert ein Herangehen an das Thema mithilfe der Auswahl des Schlagwortes Blume
- Sie planen eine Ausstellung zu berühmten Archäolog*innen und verschaffen sich einen Überblick zu vergleichbaren Objekten zu Karl Richard Lepsius. – Intendiert eine gezielte Volltextsuche nach Stichwort Lepsius
- Sie setzten sich näher mit den Ethnien aus Nordeuropa auseinander und verschaffen sich einen Überblick der Objekte. – Intendiert eine gezielte Volltextsuche nach dem Begriff Nordeuropa
Kategorienbasierte Auswertung
Die Auswertung und Ergebnisdarstellung der Testings erfolgen anhand von sechs Hauptkategorien, welche im Zuge einer qualitativen Inhaltsanalyse eruiert wurden. Die Grundlage bildeten die verschriftlichten wörtlichen Transkriptionen. Die Hauptkategorien werden einzeln aufgeführt, kurz erläutert und mit einzelnen Ankerpunkten – exemplarische Zitate der Proband*innen – belegt. Folgende sechs Hauptkategorien werden für die Auswertung und Ergebnisdarstellung näher beleuchtet:
- Verständnisprobleme
- Motivation
- Einstiegshilfen
- Nutzungsszenarien
- Navigation
- Navigationshilfen
Verständnisprobleme spiegeln sich darin wider, dass die Proband*innen Schwierigkeiten haben, die Anordnungen in der Pfad- und Wolken-Ansicht nachzuvollziehen. In der Pfad-Ansicht wurden sowohl der unabhängige Vergleich zwischen den Abbildungen, als auch die Darstellung der Ähnlichkeiten durch den Faden benannt: „Den Pfad finde ich nicht gleich verständlich, weil der sich mir nicht erschließt, auf den ersten Blick“ [Interview Nr. T 10, S. 1]. Ein ähnliches, aber von vielen Proband*innen nicht unmittelbar benanntes Problem, stellten die zusammengestellten Beziehungen der Objekte in der Wolken-Ansicht dar. „Irgendwie sind die sortiert, wobei ich jetzt gerade noch nicht ganz verstehe wie. Ich klicke einfach mal, wie die sortiert sind“ [Interview Nr. T 13, S. 1]. In beiden Ansichten haben alle Proband*innen Deutungsversuche vorgenommen und konnten, ohne sich genau sicher zu sein, die Intention der Anwendung verstehen: „Das hätte ich vermutet, dass die gerade Linie eine direkte Beziehung ist und eine gebogene […], weil die Beziehung weiter weg ist […]. Wobei es für mich merkwürdig ist, von meinem ausgewählten Objekt die Beziehung zu dem darunter stehenden, die ist nicht richtig nah dran eher weit entfernt […]“ [Interview Nr. T 11, S. 5] sowie „[r]ein optisch gehe ich davon aus, dass die in die gleiche Zeit, gleiche Themengebiete und Ähnlichkeiten gehören würden. Ich müsste mich bei ‚Lepsius‘ durchklicken, was die dann wiederum mit ihm zu tun haben“ [Interview Nr. T 10, S. 3]. Neben den Verständnisproblemen wurde von zwei Proband*innen zusätzlich angemerkt, dass die Darstellung der Ähnlichkeiten zum Teil wahllos wirke. „Da würde ich gerne das Kriterium wissen, sonst würde ich das relativ schnell in Frage stellen, ob diese Linie sinnhaft ist“ [Interview Nr. T 13, S. 3].
Einen weiteren, wesentlichen Aspekt für den Umgang mit der Anwendung bildete die Motivation der einzelnen Proband*innen. Darunter können die Voraussetzungen gefasst werden, unter welchen die Teilnehmer*innen die Anwendung verwenden würden sowie der praktische Nutzen des Prototyps für die fachliche Arbeit.
Hinsichtlich der Motivation für die Nutzung unterschieden die Proband*innen zwischen zwei Szenarien: „Für mich gibt es zwei Grundziele, warum ich so etwas mache. Entweder ich mache es als Museumsforscher und habe ein bestimmtes Ziel. Dann habe ich ganz andere Anforderungen, wie ich es als Privatmensch habe, wenn ich mir mal so eine Museumssammlung anschaue und mich darin verlieren will. Für das zweite finde ich die Wolke deutlich angenehmer, weil es mich visuell mehr anspricht, mich durchzuklicken“ [Interview Nr. T 11, S. 7]. Zwei wichtige Perspektiven kommen in diesem Zusammenhang zum Tragen: Es wird zum Einen die wissenschaftliche Perspektive, die sich an den beruflichen Praktiken der Proband*innen orientiert, benannt. Zu dieser zählt, neben einem Recherche-orientierten Umgang mit Online-Sammlungen, auch die Informationsaufbereitung der Ergebnisse mittels Listen. „Das ist die Art, wie wir arbeiten. Sich eine Tabelle generieren mit der ich dann weiterarbeiten muss. Hier würde ich Inventarnummern rüber kopieren und irgendwo anders eine Liste führen“ [Interview Nr. T 13, S. 7]. Zum Anderen wird, trotz Schwierigkeiten bei der Einordnung von Beziehungen und Ähnlichkeiten, der Mehrwert der Visualisierung und Zusammenstellungen benannt. „Auf jeden Fall […] unterstützt es [gegenüber klassischen Online-Sammlungen] sehr gut das visuelle Herangehen ohne etwas filtern zu müssen“ [Interview Nr. T 14, S. 9]. Positive Aspekte, wie unerwartete Zusammenhänge „Zufallsentdeckungen sind eine sehr schöne Sache.“ [Interview Nr. T 09, S. 3], das Hineingleiten in andere Fachgebiete oder auch der Blick auf übergreifende Sichtweisen der Sammlungen, lassen eine positive Wahrnehmung der Anwendung erkennen. „Das führt dann schneller in eine Recherche, wo man auf Sachen stößt, die man nicht unbedingt im Blick hatte, aber die thematisch zusammenhängen oder eben sammlungsbezogen.“ [Interview Nr. T 10, S. 2]
Um die Proband*innen zu den Objektansichten der einzelnen Beziehungen und Ähnlichkeiten zu führen, wurden verschiedene Aufgaben entwickelt (siehe 5.2.1 Auswahl der Proband*innen und Aufgaben). Je nach Aufgabentyp boten sich verschiedene Einstiegshilfen für die Proband*innen an. Bei der Lösung der Aufgaben gingen die Proband*innen unterschiedlich vor. Während das Vorgehen über Schlagworte themenorientierte Zugänge ermöglicht, bildete die Volltextsuche eine Option zur Bewältigung der Aufgaben, die eine konkrete Suche beispielsweise nach einem Begriff enthielten. Alle Proband*innen vermuteten, dass es sich hierbei um eine Volltextsuche handelt: „Mein Eindruck ist, dass es eine Volltextsuche ist. Weshalb ich auch die Ketten bekomme, die irgendwas mit einer Handtasche zu tun haben. Und je nachdem was ich suche, kann das auch sehr nützlich sein […]“ [Interview Nr. T 13, S. 5] und weiter „Es ist natürlich auch so, dass nicht nur Häuser kommen, sondern auch, wenn Haus Bestandteil des Namens eines Künstlers ist“ [Interview Nr. T 12, S. 2].
Wenn es darum ging, thematisch gebundene Inhalte aus der Anwendung herauszuarbeiten, wurde gezielt auf die Schlagworte in der Wolken-Ansicht zurückgegriffen. „Weil das sozusagen mein Thema ist, wenn ich sage, ich will was über Glauben, ist Sakral für mich der Begriff, der dem am nächsten kommt“ [Interview Nr. T 14, S. 2]. Die durch die Schlagworte hergestellten Beziehungen zwischen den Objekten wurden von den Proband*innen erkannt. Ein Großteil der Befragten stellte die Vermutung auf, dass diese im Museumsdokumentationssystem selbst annotiert wurden. „Es kann sein, dass [in der Datenbank] Schlagworte fehlen. Irgendwer muss irgendwie einstellen, wo diese Verwandtschaft zwischen den Bildern […], also wie groß die ist und dass sie besteht“ [Interview Nr. T 09, S. 2]. Die Verteilung der Schlagworte sowie ihre Basis zur Auswahl wurde als problematisch empfunden. „Warum bei manchen Pfeilen sind und bei manchen nicht, ist mir nicht klar und warum manche Fotos in dieser Wolke sind und manche abseits“ [Interview Nr. T 11, S. 5].
Beide Möglichkeiten stellen einen unmittelbaren Einstieg in die Sammlungen dar und wurden als Funktion genutzt. Demgegenüber las nur eine Proband*in den Einführungstext und begründete dies damit, dass sie keine Erfahrungen auf diesem Gebiet hat: „Ich bin mit dieser Seite konfrontiert und würde mir erstmal durchlesen was das ist, weil das für mich neu ist“ [Interview Nr. T 12, S. 1]. Alle weiteren Proband*innen stießen erst nach mehrfacher Bitte, die Startansicht intensiver anzusehen, auf den Einstiegstext und überflogen diesen eher beiläufig. Zwei der Proband*innen betonten, dass lange Textblöcke unbefriedigend für sie seien und nicht gelesen würden; beziehungsweise sie lieber sofort in die Wolke einsteigen wollten und somit der Einstiegstext keine Relevanz für sie habe. „Ich lese ungerne so lange Texte, wenn ich eigentlich Lust habe etwas zu entdecken“ [Interview Nr. T 14, S. 9].
Neben der Fragestellung, ob Ähnlichkeiten und Beziehungen erkannt und in einen Zusammenhang gebracht werden können, flossen die genannten möglichen Nutzungsszenarien des Prototyps in die Untersuchung ein. Im Ergebnis lassen sich drei mögliche Nutzungsszenarien ableiten:
- Für die überblicksartige Annäherung an Themen und Inhalte oder eine fachfremde Themenrecherche. „Also ich glaube ich würde sie für eine Vorrecherche nehmen. Wenn ich mich ganz allgemein einem Thema nähern will. Wenn ich schon sehr genau weiß, was ich suche, finde ich eine strukturierte Datenbank für mich einfacher, wo ich danach eine Tabelle bekomme. Aber wenn ich erstmal in verschiedene Richtungen gucke und auch noch nicht hundertprozentig genau weiß, was ich eigentlich möchte, dann finde ich es nett“ [Interview Nr. T 13, S. 6].
- Für die Suche und Auswahl von Objekten für Ausstellungen. „Wenn ich mir vorstelle, dass ich für eine Ausstellung was suche. Es wäre halt ganz wichtig, dass ich immer eine Inventarnummer habe. Irgendwas, wenn ich das Stück ausleihen will oder ein Foto anfrage für ein Katalog, dass ich das sofort identifizieren kann. Was auch interessant ist, dass für mich Material und Technik angegeben ist sowie Maße. Von daher wäre ich, wenn ich wirklich für eine Ausstellung suche, ganz glücklich“ [Interview Nr. T 13, S. 2].
- Für den explorativen Einstieg in die Sammlungen der Staatlichen Museen zu Berlin. „[W]enn ich mich ganz allgemein [informieren möchte], wenn ich mir vorstelle, ich kenne die Staatlichen Museen nicht und will mal so gucken, was es da eigentlich gibt.“ [Interview Nr. T 13, S. 6]
Ein weiteres untersuchtes Themenfeld bildete die Navigation der Proband*innen innerhalb der Anwendung. Im Fokus der Untersuchung stand dabei, wie sich die Teilnehmenden in der Wolken- und Pfad-Ansicht bewegt haben, sowie ob der Wechsel zwischen diesen Interfaces klar nachvollziehbar war. Die Untersuchung hat gezeigt, dass sich die Proband*innen wenig mit den Objekten und den Clustern in der Wolken-Ansicht auseinandersetzten, wobei hier die Art der Aufgabenstellung die Interaktion beeinflusste. Zudem betonten einige Proband*innen einen Verlust der Orientierung innerhalb der Wolke: „Ich hätte Angst mich in der Wolke zu verlieren und wie meine Recherche da weitergegangen wäre“ [Interview T 10, S. 3]. Demgegenüber fand eine intensive Auseinandersetzung der Proband*innen mit der Pfad-Ansicht statt, was eingeübte Arbeitsweisen der Wissenschaftler*innen verdeutlichen: „[i]ch glaube, dass liegt auch daran, wie man gewohnt ist zu suchen. Ich mache sowas den Tag über sehr häufig, bis ich unterschiedliche Objekte, Daten suche. Ich arbeite immer über die Tabellen-, Listenfunktion“ [Interview Nr. T 13, S. 6]. Grundsätzlich wurde die Navigation in der Pfad-Ansicht von den meisten der Proband*innen positiv bewertet. Das Vergrößern und der Wechsel zwischen den Detailabbildungen sowie die Performance wurden als sehr zufriedenstellend eingestuft. „Ich finde es ganz ansprechend, wie es wechselt [Klickwechsel zwischen Abbildungen]. Nicht das harte Wechseln, sondern das rein fliegen, finde ich ganz angenehm“ [Interview Nr. T 11, S. 2]. Der Wechsel von der Wolken- zur Pfad-Ansicht konnte nur zum Teil visuell nachvollzogen werden und führte zur Verwirrung oder Fehlinterpretation: „Dass es sich ändert [von Wolken- zu Pfad-Ansicht] war für mich irritierend und wenn ich nicht nochmal auf die Wolke geklickt hätte, wüsste ich nicht, wie sich die Objekte verhalten dazu“ [Interview Nr. T 11, S. 6].
Zur Durchführung der Aufgaben wurden verschiedene Navigationshilfen wie das Hervorheben (Highlighting) ähnlicher Objektabbildungen, das Hinein- und Herauszoomen sowie die in der Anwendung vorhandenen Buttons in die Betrachtung einbezogen.
Die durch das Highlighting gegebene visuelle Unterstützung zum Herausbilden der Beziehungen durch Hervorhebung und Ausgrauen der Objekte wurde von den Proband*innen erkannt: „Ich bin in einer dieser Kategorien, vermutlich in Schmuck, drinnen und sehe das bestimmte Objektfotos nicht mehr grau hinterlegt sind, sondern hervorgehoben sind“ [Interview Nr. T 13, S. 4]. Die Auflösung der Abbildungen in der Wolken-Ansicht wurden jedoch als problematisch empfunden. Über die Hälfte der Proband*innen fand diese sehr klein und deuteten sie im ersten Aufschlag als Punkte oder Rechtecke. „Es ist sehr klein. Bis man es erkennen kann, ist man ziemlich weit drinnen. Ich fände es hilfreich, wenn ich hier drüber fahre, die Punkte als größeres Bild aufblenden würde“ [Interview Nr. T 10, S. 5]. Auch das Hineinzoomen war für viele Proband*innen nicht ausreichend. „Weitere Zoom-In-Stufen in der Wolke wären gut“ [Interview Nr. T 09, S. 2].
Sowohl der Wolke-Button als auch der Button Zeige ähnliche Objekte als Pfad wurden nicht intuitiv entdeckt und erst auf Nachfrage, die Detailseite eingehender zu betrachten, erkannt. Einige Proband*innen ordneten dem Button Wolke eine andere Funktion zu. „Ich dachte, wenn ich hier auf den Pfeil [Wolke-Button] zurück gehe, klappt es sich wieder ein. Es ist ein Zurück in dem Sinne. Dafür finde ich gar keinen Knopf. Ich dachte der Pfeil [Wolke-Button] nach links heißt wieder zusammenschieben“ [Interview Nr. T 11, S. 3].
Resümee
Im Gesamtergebnis kann festgehalten werden, dass im Laufe des Testings die eingangs formulierten Annahmen belegt wurden. Bedingt durch die Aufgabenstellung wurden entweder gezielt Schlagworte in der Wolken-Ansicht zur Lösungsfindung verwendet oder eine Volltextsuche mittels beispielhafter Begriffe. In diesem Zusammenhang lässt sich feststellen, dass die beruflichen Praktiken der Befragten den Umgang mit dem Prototyp beeinflussen. Unabhängig von der Aufgabenstellung wurde die Volltextsuche von allen Proband*innen ausprobiert. Das Eruieren von Lösungen mithilfe von Schlagworten führte zu einer intensiveren Auseinandersetzung mit der Wolken-Ansicht. Die Einordnung der Schlagworte, ihre Verteilung und Zusammensetzung waren für die Proband*innen nicht immer eindeutig, was dazu führte, dass auch die Beziehungen der Objekte in der Wolken-Ansicht nur bedingt verstanden wurden. Ähnliches konnte für die Einordnung des Faden-Ausschlages und der Beziehungen der Objekte in der Pfad-Ansicht beobachtet werden. Die Teilnehmenden konnten dem Ausschlag nicht folgen und die Beziehungen zwischen dem von ihnen ausgewählten Objekt und den darunter angeordneten nicht nachvollziehen. Die Beziehungen und Ähnlichkeiten zwischen den Objekten konnten demgegenüber von den Proband*innen sehr treffend gedeutet werden und führten zu einer neugierigen Auseinandersetzung mit fachfremden Objekten. In diesem Zusammenhang wurden die Aspekte des Nutzens und der Motivation der Anwendung dargelegt. Die von den Proband*innen formulierte Trennung zwischen einer museumsspezifischen, Recherche-orientierten Motivation und einer Verwendung im privaten Kontext verdeutlichen, dass sich die mit der Nutzung verbundenen Bedarfe im Arbeitsumfeld und in der Freizeit unterscheiden und werfen die Frage möglicher Nutzungsszenarien auf. Bei den Proband*innen wurde die Unsicherheit hinsichtlich einer ausreichenden Eignung des Instruments für die gezielte Suche und Aufbereitung der Ergebnisse deutlich, während der spielerische Aspekt und der erweiterte übergreifende Blick auf die Sammlungen positiv angemerkt wurde. Die Nennung möglicher Nutzungszenarien ‒ in Vorbereitung zur Objektauswahl für Ausstellungen, zur Recherche fachfremder Themen sowie der explorative Einstieg in die Sammlungen der Staatlichen Museen zu Berlin ‒ zeigen, dass die Zielsetzung des Prototyps erkannt wurde. Die Navigation innerhalb der Anwendung konnte von den Proband*innen gut nachvollzogen werden. Auch wenn der Wechsel zwischen der Wolken- und Pfad-Ansicht für die Teilnehmer*innen nicht immer visuell nachvollziehbar und die Auflösung der Abbildungen teilweise als zu klein empfunden wurde, hat die Anwendung den Proband*innen eine interaktive Auseinandersetzung mit den Objekten ermöglicht.
Die aufgeführten Ergebnisse verdeutlichen, dass wichtige Zielsetzungen mit der Anwendung realisiert werden konnten (siehe Einleitung). Durch die Visualisierung von Schnittmengen, anhand von Ähnlichkeits-Anordnungen, ist der Blick der Proband*innen auf die Bestände der Sammlungen erweitert worden. Eigene vertraute Themen sind in Beziehung zu fachfremden Objekten gesetzt worden und führten bei den Proband*innen zur Formulierung neuer Fragestellungen. Darüber hinaus ist die Möglichkeit einer explorativen Erkundung der Sammlungen der Staatlichen Museen zu Berlin mittels alternativer spielerischer Visualisierungsformen festgestellt worden. Das positive Feedback der Proband*innen und die Formulierung von weiteren Bedarfen (siehe 6 Fazit und Ausblick) deuten darauf hin, dass zukünftig auch andere Bestände der Staatlichen Museen zu Berlin im Prototyp involviert werden könnten und eine dynamische Weiterentwicklung angeregt werden könnte.
Fazit und Ausblick
Aus Sicht der Forschung zur Visualisierung kultureller Sammlungen tauchten im Projektverlauf einige Fragestellungen und Herausforderungen auf, welche in einem zukünftigen Projekt schwerpunktmäßig Beachtung finden könnten. Zunächst lässt sich hier der Aspekt der Verwendung maschinellen Lernens nennen, der im Kontext des Projekts kritisch ausprobiert wurde. Denkbar wäre zukünftig eine Verfeinerung der Ähnlichkeits-Anordnung vorzunehmen, sodass mehr sichtbare Cluster und auch Schlagworte als Ausgangspunkte für eine Exploration zur Verfügung stehen könnten.
Die automatische Verschlagwortung über Sammlungsgrenzen hinweg wurde im Projektverlauf divers diskutiert ‒ hier konnte das Projekt zwar einen ersten Versuch unternehmen, allerdings bisher keine belastbaren Ergebnisse liefern. Das Experiment hat gezeigt, dass eine Auswahl der Schlagworte in einem gemeinsamen co-kreativen Austausch zwischen den Projektmitgliedern und Kurator*innen unentbehrlich ist, da der maschinelle Algorithmus keine kontext- und sammlungsspezifischen Inhalte besitzt oder auswerten kann. Für eine maschinelle Verschlagwortung müssten die vorhandenen Modelle auf den Use Case der Sammlungsvisualisierung angewandt und spezifisch trainiert werden. In Anlehnung an die Frage zur Handhabung der zukünftigen Erweiterung und Anreicherung der Schlagworte, könnten Laien ihr Wissen mit einbringen. Durch Social Tagging, bei dem User*innen eigene Schlagworte für Themen vergeben, könnte die Relevanz und Trefferquote der Themen erhöht werden. Dies würde allerdings einen redaktionellen Prozess bedeuten, welcher hinsichtlich der Qualität der Schlagworte und des damit verbundenen Aufwands kritisch hinterfragt werden müsste. Für eine potentielle Weiterentwicklung des Projekts stellt sich darüber hinaus die Frage, ob die algorithmische Anordnung für mehrere und diverse Sammlungen skalierbar ist. Dieser Ansatz wurde von allen Proband*innen der Evaluation begrüßt und als Potenzial gesehen. Hier ist einerseits die Frage, ob eine Clusterbildung hinsichtlich noch heterogenerer Sammlungsbestände überhaupt gelingen würde und ob eine größere Anzahl an Objekten Probleme in der Performance der Anwendung mit sich bringen würde.
Weitere Perspektiven boten die Ergebnisse der Evaluation, welche nicht alle final in den Prototypen einfließen konnten. Hier lassen sich insbesondere eine Verfeinerung der Suche und erweiterte Hilfen zum Einstieg in die Visualisierung nennen. Die Volltextsuche brachte im Prototypen manchmal Probleme mit sich, wenn beispielsweise Suchbegriffe wie Ring oder Bart zu Gemälden eines Malers mit dem Namen Spring oder Objekten mit dem Titel Bartholdy führten. Hier wäre eine facettierte Suche über bestimmte Datenfelder denkbar, der Vorschlag von Schlagworten und Ergebnissen schon während des Suchvorgangs, sowie ein Ranking der Suchergebnisse nach Relevanz. Zum Einstieg in die Visualisierung könnte zukünftig ein Lupen- bzw. Fish-Eye-Effekt angewendet werden, welcher beim Hovern über die Punkte in der Wolke eine vergrößerte Vorschau auf die Abbildungen zulässt. Des Weiteren könnten durch Verlinkungen zu anderen Fach- und Onlineportalen verschiedene Objektinformationen, wie Angaben zu Orten, Personen oder Kulturkreisen angereichert werden und die thematischen Kontexte so erweitern.
Was Verständnisprobleme bezüglich der Plausibilität der Ähnlichkeitsanordnungen betrifft, so ist es nicht unerwartet, dass nicht alle Anordnungen vollständig nachvollzogen werden können, da fehlerhafte Nähen oder Abstände in der Ähnlichkeitsanordnung auf globaler Ebene in der Regel zur Natur der Methode gehören. Die Nachvollziehbarkeitsprobleme in der Pfad-Ansicht führen wir vor allem auf die bewusste Mischung von Titel- und Bildähnlichkeit zurück, welche durch die Mischung weniger offensichtlich ist, als es bei einer Anordnung auf reiner Bildähnlichkeit zum Beispiel möglich wäre. Dies wurde jedoch mit dem Ziel einer besseren Durchmischung der Sammlungen und zusätzlicher unerwarteter Verknüpfungen als Kompromiss in Kauf genommen. Für beide Nachvollziehbarkeits-Probleme sehen wir insbesondere eine bessere Vermittlung der Berechnungen als Lösungsmöglichkeit. Generell könnte der Einstieg in die Visualisierung über eine Hilfe oder Narration noch einmal genauer betrachtet werden; Erfahrungen aus früheren Projekten zeigen immer wieder ein Dilemma zwischen dem Erklärungsbedarf der Visualisierungen und der Bereitschaft der Nutzer*innen, entsprechende Erklärungen in textlicher Form zu lesen. Hier könnten alternative Formen erforscht und mit Nutzer*innen getestet werden, beispielsweise als wiederkehrende Step-by-Step Anleitungen in Pop-Up-Fenstern beim ersten Besuch der Anwendung oder durch Integration eines zentralen Info-Buttons.
Das Ziel des Projekts war es, eine experimentelle sammlungsübergreifende Visualisierung zur Exploration heterogener Objekte zu erstellen. Die Nutzung von algorithmischen Methoden hat sich dabei in diesem Projekt als Ergänzung erwiesen, jedoch im Prozess und der Evaluation auch einige Schwierigkeiten und Problematiken offengelegt. Eine interdisziplinäre Zusammenarbeit und kritische Betrachtung von algorithmischen Methoden, insbesondere unter Einbezug der Sammlungsexpert*innen, war dementsprechend unerlässlich und führte zu einer kuratierten Ergänzung von Schlagworten zu den maschinell generierten Darstellungen. Das Ergebnis ist ein Visualisierungsprototyp, der auf einem Wechsel zwischen globalen und lokalen Ähnlichkeiten basiert. Während nach einer ersten qualitativen Auswertung festgestellt werden kann, dass die Vermittlung neuartiger Visualisierungsformen und zugrunde liegender Algorithmen weiterhin eine Herausforderung darstellen, hat die Visualisierung insbesondere im Bezug auf freie Exploration und unerwartete Entdeckungen sehr positives Feedback hervorgerufen.
Quellenverzeichnis
Abadi, Martin, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, et al. “Tensor Flow: A System for Large-Scale Machine Learning.” In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, 265–283. Berkeley: USENIX Association, 2016. https://www.usenix.org/system/files/conference/osdi16/osdi16-abadi.pdf.
Beyer, Lucas und Alexander Kolesnikov. “Open-Sourcing BiT: Exploring Large-Scale Pre-training for Computer Vision”. Zuletzt geändert im Mai 2020. https://ai.googleblog.com/2020/05/open-sourcing-bit-exploring-large-scale.html.
Chen, Ko-le, Marian Dörk, and Martyn Dade-Robertson. “Exploring the Promises and Potentials of Visual Archive Interfaces.” In Proceedings of the 2014 IConference, 735–741. Urbana-Champaign: IDEALS, 2014. https://mariandoerk.de/papers/iconf2014_amber.pdf.
Dörk, Marian, Boris Müller, Stange Jan-Erik, Johannes Herseni, and Katja Dittrich. “Co-Designing Visualizations for Information Seeking and Knowledge Management.” Open Information Science 4 (2020): 217–235. https://dx.doi.org/10.1515/opis-2020-0102.
Dörk, Marian, Rob Comber, and Martyn Dade-Robertson. “Monadic Exploration: Seeing the Whole through Its Parts.” In Proceedings of the 32nd Annual ACM Conference on Human Factors in Computing Systems ‒ CHI ’14: 1535–44. Toronto, Ontario, Canada: ACM, 2014. https://doi.org/10.1145/2556288.2557083.
Dörk, Marian, Sheelagh Carpendale, and Carey Williamson. “The Information Flaneur: A Fresh Look at Information Seeking.” In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems: 1215–1224. New York: ACM, 2011. https://doi.org/10.1145/1978942.1979124.
D3.js. https://d3js.org.
Gortana, Flavio, Franziska von Tenspolde, Daniela Guhlmann, and Marian Dörk. “Off the Grid: Visualizing a Numismatic Collection as Dynamic Piles and Streams.” Open Library of Humanities 4, no. 2 (2018): 30. https://doi.org/10.16995/olh.280.
Hinrichs, Uta, Stefania Forlini, and Bridget Moynihan. “In Defense of Sandcastles: Research Thinking through Visualization in Digital Humanities.” Digital Scholarship in the Humanities 34, Supplement 1 (2019): 80–99. https://doi.org/10.1093/llc/fqy051.
Isenberg, Petra, Torre Zuk, Christopher Collins, and Sheelagh Carpendale. “Grounded Evaluation of Information Visualizations.” In Proceedings of the 2008 Conference on BEyond Time and Errors: Novel EvaLuation Methods for Information Visualization ‒ BELIV ’08, 1. Florence, Italy. New York: ACM, 2008. https://doi.org/10.1145/1377966.1377974.
Jupyter. https://jupyter.org.
Kolesnikov, Alexander, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. “Big Transfer (BiT): General Visual Representation Learning.” ArXiv e-prints (Mai 2020). http://arxiv.org/abs/1912.11370.
Konrad, Klaus. “Lautes Denken.” In Handbuch Qualitative Forschung in der Psychologie, hg. von Günter May und Katja Mruck, 476–490. Wiesbaden: Springer Verlag, 2010.
McInnes, Leland, John Healy, and James Melville. “UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction.” ArXiv e-prints (2020). http://arxiv.org/abs/1802.03426.
Observable. https://observablehq.com.
Pixijs. https://www.pixijs.com.
Shneiderman, Ben. “The Eyes Have It: A Task by Data Type Taxonomy for Information Visualizations.” In Proceedings 1996 IEEE Symposium on Visual Languages, 336–343. New York: IEEE, 1996.
Stahnke, Julian, Marian Dork, Boris Muller, and Andreas Thom. “Probing Projections: Interaction Techniques for Interpreting Arrangements and Errors of Dimensionality Reductions.” IEEE Transactions on Visualization and Computer Graphics 22, no. 1 (2016): 629–38. https://doi.org/10.1109/TVCG.2015.2467717.
Stefaner, Moritz. “Multiplicity: A Collective Photographic City Portrait.” Truth & Beauty (blog). Zuletzt geändert 2018. https://truth-and-beauty.net/projects/multiplicity.
Svelte. https://svelte.dev.
Tietmeyer et al. “Sammlungskonzept des Museums Europäischer Kulturen Staatliche Museen zu Berlin.” Zuletzt geändert im Mai 2019. Letzter Zugriff im Dezember 2020. https://www.smb.museum/fileadmin/website/Museen_und_Sammlungen/Museum_Europaeischer_Kulturen/02_Sammeln_und_Forschen/MEK_Sammlungskonzept.pdf.
Vane, Olivia. “Visualising the Royal Photographic Society Collection: Part 2.” V&A Blog – News, Articles and Stories from the V&A (blog). Zuletzt geändert im August 2018. https://www.vam.ac.uk/blog/digital/visualising-the-royal-photographic-society-collection-part-2.
Whitelaw, Mitchell. “Generous Interfaces for Digital Cultural Collections.” Digital Humanities Quarterly 9, no. 1 (2015).
Windhager, Florian, Paolo Federico, Gunther Schreder, Katrin Glinka, Marian Dork, Silvia Miksch, and Eva Mayr. “Visualization of Cultural Heritage Collection Data: State of the Art and Future Challenges.” IEEE Transactions on Visualization and Computer Graphics 25, no. 6 (2018): 2311–30. https://doi.org/10.1109/TVCG.2018.2830759.
Yang, Yinfei, Daniel Cer, Amin Ahmad, Mandy Guo, Jax Law, Noah Constant, Gustavo Hernandez Abrego, Steve Yuan, Chris Tar, Yun-Hsuan Sung, Brian Strope, Ray Kurzweil. “Multilingual Universal Sentence Encoder for Semantic Retrieval”. ArXiv e-prints (2019). https://doi.org/10.48550/arXiv.1907.04307.
Weitere Ergebnisse im Teilprojekt

Digitale Vermittlungstools
Nachgenutzt – das „Display“ Starterkit bildet die Grundlage zur Web-App „Bronzen wie Tiere“
Staatliche Museen zu Berlin – Preußischer Kulturbesitz
Digitale Vermittlungstools
Online Sammlungen der Staatlichen Museen zu Berlin 2.0
Staatliche Museen zu Berlin – Preußischer Kulturbesitz